Top Data Science Tools in 2023
Learn via video course

Introduction
Data has become an integral part of any organization's decision-making and strategic planning processes.
With the increase in size and complexities of enterprise data, organizations are investing more in professionals, Data science tools, and technologies to analyze their data to gain valuable business insights for the success and growth of the company.
As per a survey by NewVatange Partners in , % of the organizations have increased their investment in Big Data and Data Science initiatives.
Another report by the market research firm International Data Corporation (IDC) in has predicted that investment in Big Data and Analytics systems will grow at a compound annual growth rate (CAGR) of % through . This will ensure that the future of Data Science is promising and will be in demand for the next decade.
Data Science is a vast field and involves processing data in various ways. As an aspiring Data Scientist, you should understand the best Data Science tools available for efficiently implementing any Data Science task.
This article provides a list of various Data science tools used in Data Science, and having good knowledge of these tools can help you build a promising career as a Data Scientist.
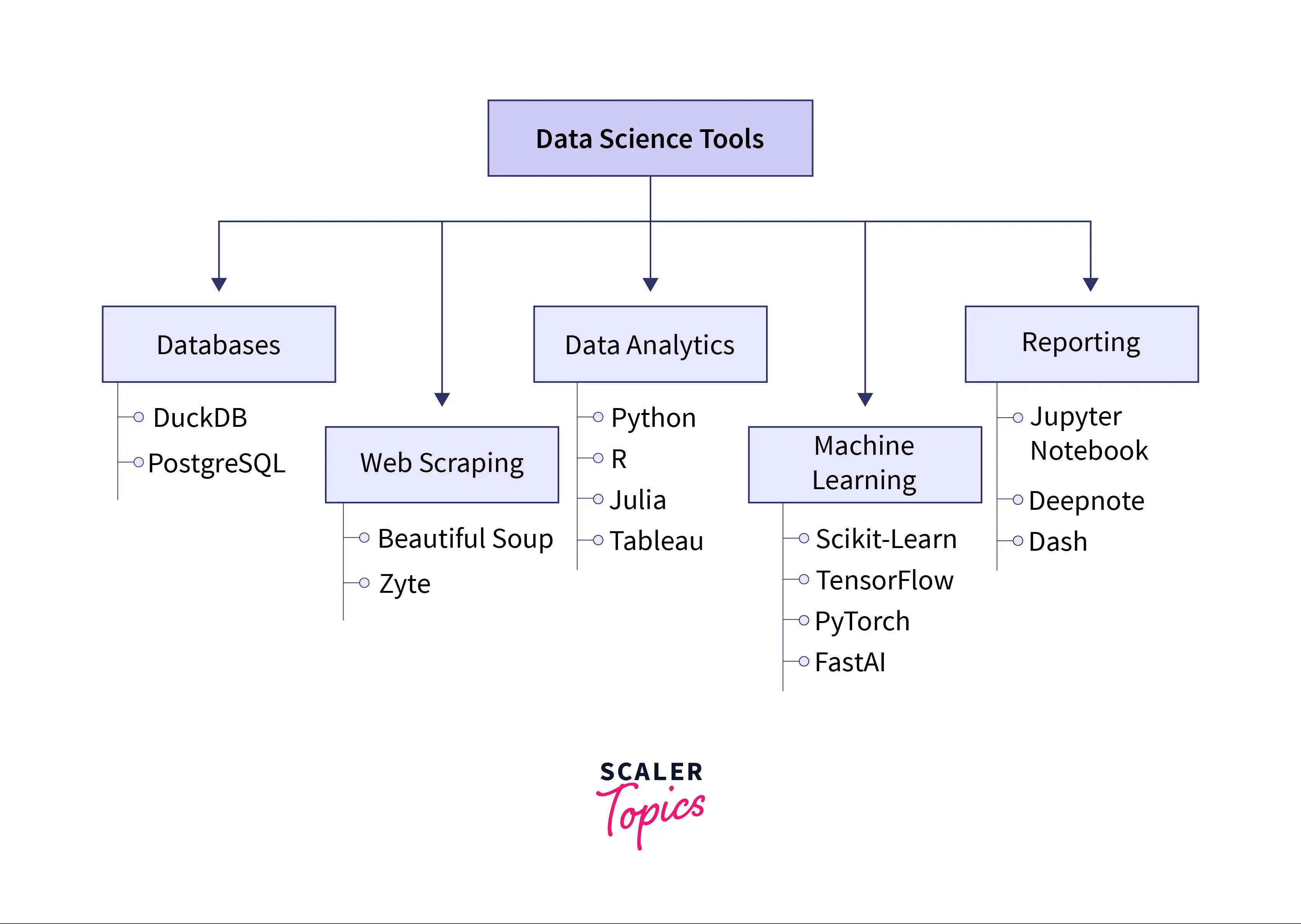
Categories for Data Science Tools
Data Science Tools help implement various steps involved in a Data Science project such as Data Analysis, Data Collection from databases and websites, Machine Learning model development, communication results by building dashboards for reporting, etc. Based on the different kinds of tasks involved, Data Science tools can be divided into five categories as mentioned below :
- Database
- Web Scraping
- Data Analytics
- Machine Learning
- Reporting
In the subsequent sections, we will get into detail to learn more about what kind of tools are available in each category.
Database
Organizations store enterprise data in different kinds of databases at the same time. A Database can be defined as a structured or unstructured set of data stored in a computer’s memory or on the cloud that is accessible in many ways.
As a Data Scientist, you will be required to interact with databases to collect the data stored in them for further analysis. Having a good understanding of different kinds of databases can help you manage and retrieve information from them efficiently. A few of the most common databases used in Data Science include :
SQL
- SQL stands for Structured Query Language that is used by Data Scientists to query, update, and manage relational databases and extract data. For years, organizations have been storing their data in relational databases due to their simplicity and ease of maintenance.
- As part of their job, Data Scientists are required to collect and join large amounts of data from disparate relational databases for further analysis. So, Data Scientists must have an in-depth understanding of SQL language and its concepts to query and manage SQL-based databases and collect required data for further analysis.
DuckDB
- DuckDB is a relational table-oriented database management system that also supports SQL queries to perform analysis. It is free and open source and comes with various features such as faster analytical queries, simplified operations, etc.
- DuckDB also provides integration with various programming languages used in Data Science, such as Python, R, Java, etc. You can use these languages to create and register a database and play around with it.
PostgreSQL
- PostgreSQL is an open-source relational database system that was developed in the . It takes an object-oriented approach to the databases.
- PostgreSQL is quite popular in the Data Science industry due to its ability to scale when working with large amounts of structured and unstructured data. According to the Stack Overflow Developer Survey, PostgreSQL is the second most popular database among Data Scientists, Data Engineers, and Developers.
- The popularity of PostgreSQL means that this database is widely used by many organizations to store data. So students or experienced professionals who want to build a career as a Data Scientist should consider learning and understanding this relational database management system.
Web Scraping
Web scraping can be defined as the process of extracting content and data from a website. As a Data Scientist, sometimes you may be required to perform Web Scraping to collect data from various websites for further analysis.
Some of the use cases of Web Scraping in Data Science are performing stock analysis by collecting companies' financial data, competitors analysis, lead generations, market research, etc.
The steps mentioned below are typically used in a Web Scraping process:
- Identify the target website.
- Collect URLs of all the pages which you want to extract data from.
- Make HTTP requests to these URLs to get the HTML content of the pages.
- Find the required data to be scraped in the HTML.
- Save the data in a JSON or CSV file to load it into a Dataframe.
A few of the most common tools or libraries used by Data Scientists for Web Scraping include:
Beautiful Soup
- Beautiful Soup is a library in Python language to collect and extract data from HTML or XML files. It is an easy-to-use tool to collect data from Websites by reading their HTML content.
- This library can help Data Scientists or Data Engineers implement automatic Web Scraping which is an important step in fully-automated data pipelines.
Zyte
- Zyte is a cloud-based platform where you can host, run, and manage your Web Crawlers and Web Scrapers. It is an easy-to-use tool and provides fully automated web scraping solutions for your Data Science projects.
Data Analytics
Once the data is collected from various databases or websites, Data Scientists need to examine this data to discover underlying patterns and trends in it. Data Scientists store collected data in Dataframes and perform exploratory data analysis (EDA) on it by applying various statistical analysis techniques (mean, mode, standard deviation, variance, correlation, etc.) and visualization methods (histogram, bar charts, box plots, density plots, heatmap, etc.) using a programming language such as Python, R, etc. We have listed a few of the most common programming languages and tools used by data scientists to examine the datasets.
Python
- Python is the most popular and widely used programming language among Data Scientists. One of the main reasons for Python’s popularity in the Data Science community is its ease of use and simplified syntax, making it easy to learn and adapt for people with no engineering background. Also, you can find a lot of open-source libraries along with online documentation for the implementation of various Data Science tasks such as Machine Learning, Deep Learning, Data Visualization, etc.
- A few of the most common Python libraries used by Data Scientists include:
- Pandas:
It is the best library for data manipulation and wrangling. Pandas has a lot of in-built functions to explore, visualize and analyze the data in many ways. - NumPy:
It is used frequently by Data Scientists to perform operations on large arrays and matrices. All of the operations in NumPy are vectorized methods that enhance execution speed and performance. - SciPy:
It provides functions and methods to perform any kind of inferential or descriptive statistical analysis of the data. - Matplotlib:
Matplotlib is a handy library that provides methods and functions to visualize data such as graphs, pie charts, plots, etc. You can even use the matplotlib library to customize every aspect of your figures and make them interactive. - Seaborn:
It is an advanced version of the matplotlib library that enables Data Scientists to plot complex visualization methods such as histograms, bar charts, heatmaps, density plots, etc with a few lines of code. Its syntax is much easier to use compared with matplotlib and provides aesthetically appealing figures. - Plotly:
This library provides tools and methods to plot interactive figures.
- Pandas:
R
- After Python, R is the second most popular programming language used in the Data Science community. It was initially developed to solve the statistical problem but now it has evolved into a complete Data Science ecosystem.
- Dpylr and readr are the most popular libraries to load the data and perform data augmentation and manipulation.
- You can use ggplot2 to plot the data using various visualization methods.
Julia
- Julia is an emerging programming language, and it has recently gained popularity in the Data Science community. It is a high-level and general-purpose language that can be used to write code that is fast to execute and easy to implement for solving various scientific problems. It was built for scientific computing, machine learning, data mining, large-scale linear algebra, and distributed and parallel computing. Julia can match the speed of popular programming languages like C, and C++ during Data Science operations.
- Julia provides packages such as CSV to load the data into Dataframes. It has other packages as well, such as Plots, Statistics,, etc., to perform exploratory data analysis (EDA) on Dataframes.
Tableau
- Tableau is a data visualization tool where you can visualize large, complex data using various methods without using any programming language. It is an excellent tool for quickly creating reports for impactful and insightful visualizations.
QlikView
- QlikView is guided analytics or business intelligence tool that enables the rapid development of analytics applications and dashboards.
- It is very simple and intuitive to use. It allows you to search across all data directly and indirectly and offers Data Visualization in a meaningful and innovative way.
Machine Learning
Machine learning is a field in Computer Science that enables systems to learn and improve from experience without being explicitly programmed. Building and developing machine learning and deep learning-based predictive or prescriptive models are the most important part of the job of a Data Scientist. A Data Scientist must have an in-depth understanding of a wide range of Machine Learning algorithms spanning classification, regression, clustering, deep learning, etc. Below are the most widely used libraries or tools to develop a machine learning model.
Scikit-Learn (sklearn)
- It is the most popular Machine Learning Python library that provides a simple, optimized, and consistent implementation for a wide array of Machine Learning techniques.
- It is an open-source library built upon NumPy, Matplotlib, and Scipy. Scikit-learn can be used to develop a variety of Machine Learning models but it lacks support when it comes to Deep Learning. It also provides other functions such as creating a dataset for a machine learning problem such as classification, regression, etc., normalizing the features, splitting the training and test data sets, etc.
TensorFlow
- Tensorflow was launched by Google and mainly focuses on implementing deep learning techniques. It supports CPU or GPU training to develop complex and deep neural network architectures.
- To easily access and use the Tensorflow ML platform, Data Scientists use Keras as a programming interface. It's an open-source Python library that runs on top of TensorFlow. Using TensorFlow and Keras, you can train a wide variety of Deep Learning models such as Artificial Neural Networks, Convolutional Neural Networks, Recurrent Neural Networks, Autoencoders, etc.
PyTorch
- PyTorch is another Machine Learning library developed by the Facebook AI group to train and develop Deep Learning based models. It is relatively new compared with Tensorflow but it has gained momentum due to its enhanced performance.
FastAI
- FastAI is a library that is built on top of PyTorch. It's an open-source deep learning library that allows Data Scientists to quickly and easily train deep learning models.
Reporting
Once data analysis is completed and machine learning models are developed, data scientists must communicate findings and recommendations to the business stakeholders. A good reporting tool is the most efficient way to communicate the results. We have listed down below a few of the most common reporting tools used by Data Scientists.
Jupyter Notebook
- Jupyter Notebook is an open-source web application that allows interactive collaboration among Data Scientists, Data Engineers, and other Data Science professionals. It also supports all the major programming languages used by Data Scientists.
- It provides a document-centric experience where you can write the code, visualize the data, and showcase your results in a single-page document known as a notebook.
Google Cloud Platform (GCP)
- Google Cloud Platform is a cloud computing platform developed by Google that offers a variety of tools and methods to help Data Scientists extract actionable information from massive data sets.
- GCP provides you with a free tier of the computing platform and allows you to publish and share your work with other Data Scientists as well. It also offers a comprehensive data science toolkit where you can find relevant courses and codes for best practices to build your Data Science solutions.
Deepnote
- It is a cloud-based notebook platform focusing on collaboration between teams. It also comes with multiple pre-integrated tools such as GitHub, PostgreSQL, etc.
- The platform provides you with free CPU hours and allows you to publish your notebooks in the form of articles.
Dash
- It is used to create interactive dashboards and can be used for multiple use cases such as monitoring the metrics/KPIs, communicating the results by visualizing the data, etc.
- Dash is built on Plotly.js and React.js libraries and it supports all the popular programming languages such as Python, R, Julia, etc. to build a user interface quickly.
Conclusion
Data Scientists are in high demand and are one of the highest-paid professionals across industries. With the growth in the size of the data, organizations have increased their investment in Big Data and Data Science solutions and are looking for professionals who can examine this data and derive valuable business insights which can drive the decision-making process of the company. This means that demand for Data Scientists will also be high in the next decade.
The U.S. Bureau of Labor Statistics has estimated a 22 percent growth in data science jobs during . Whether you are a student or an experienced professional, building a career as a Data Scientist could be a smart move as this job offers a lucrative and promising career path.
In this article, we have discussed various Data science tools. Understanding these Data science tools can help you get your first Data Scientist job and excel in this career path.
If you want to start a career in Data Science, check out Scaler's Data Science Course.