One Hot encoding
Learn via video course

Overview
One Hot Encoding can be defined as a process of transforming categorical variables into numerical features that can be used as input to Machine Learning and Deep Learning algorithms. It is a binary vector representation of a categorical variable where the length of the vector is equal to the number of distinct categories in the variable, and in this vector, all values would be 0 except the ith value which will be 1, representing the ith category of the variable.
Scope
- This article describes what One Hot Encoding is and when it should be used.
- This article also shows the implementation of One Hot Encoding using Pandas and Scikit-Learn using Python language.
What Is One Hot Encoding
As One Hot Encoding is used to process categorical variables, let’s first understand them before getting into One Hot Encoding.
Categorical Variables/Features
A typical dataset in any Data Science project consists of numerical and categorical features. While numerical features can contain only numbers, i.e., integers or decimals, categorical features can be referred to as a variable that can only contain a limited and fixed number of categories or labels. A few examples of categorical features include -
- A color variable with values red, blue, and green
- A country variable with values India, USA, and Germany
- A gender variable with values Male, Female
- A product category variable with values Smartphone, Headphone, Computer.
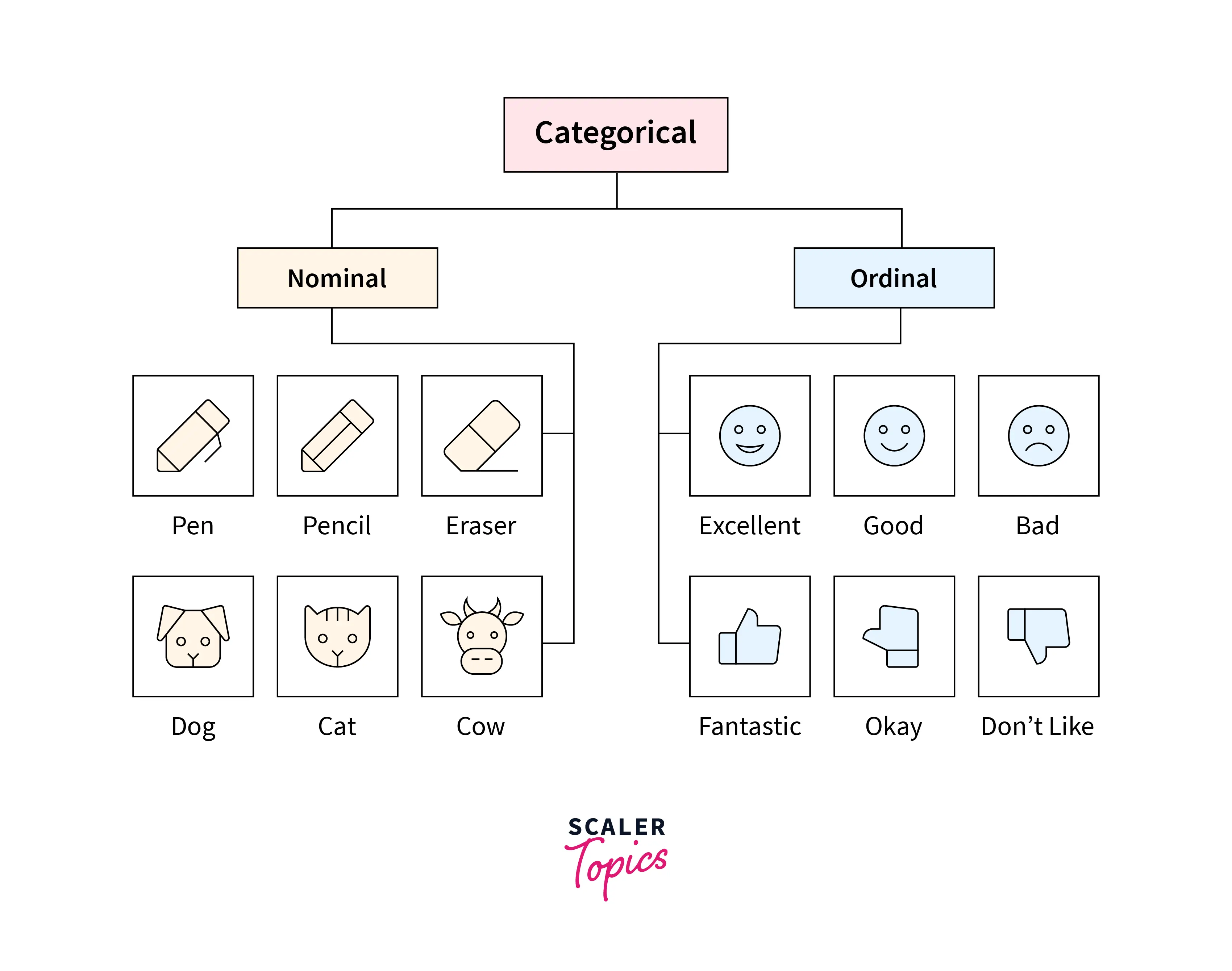
Further, categorical features/variables can be divided into two categories as described below -
-
Ordinal Categorical Variable - Ordinal variables have clear, natural, and intrinsic ordering to their categories. A few examples of ordinal variables are economic status (low income, middle income, high income), educational experience (high school, bachelor's, master’s), customer feedback ratings (strongly dislike, dislike, neutral, like, strongly like), etc.
-
Nominal Categorical Variable - Categories in nominal variables have no relationship with each other. For example, age (male, female, transgender), colors (blue, red, green, yellow), blood group (A+, B+, O+, O-), etc.
Limitations with Categorical Variables
Most Machine Learning and Deep Learning algorithms require input and output variables/features to be in numerical format. In real-world datasets, many important features are not numeric but rather categorical. As these categorical features are essential to improve the accuracy of ML models, therefore these categorical features need to be transformed/converted into a numeric format so that these can be used in training and fitting Machine Learning algorithms. While numerous techniques exist to transform these features into the numerical format, the most used and common technique is One Hot Encoding.
One Hot Encoding
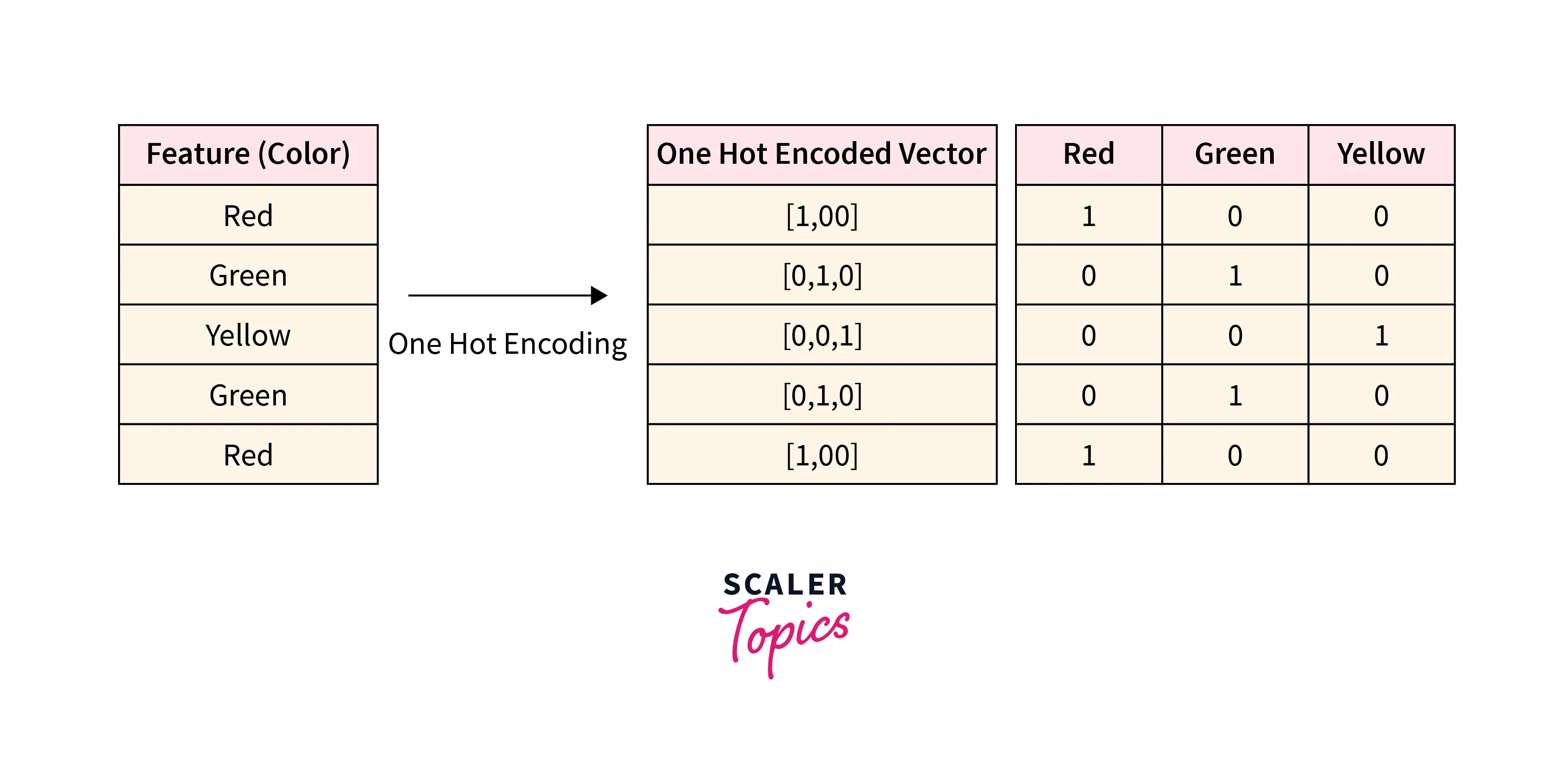
One Hot Encoding can be defined as a process of transforming categorical variables into numerical format before fitting and training a Machine Learning algorithm. For each categorical variable, One Hot Encoding produces a numeric vector with a length equal to the number of categories present in the feature. If a data point belongs to the ith category, then all values in the resulting vector would be 0 except for the ith value, which will be 1.
Let’s take an example to understand One Hot Encoding better. Suppose we have a categorical feature color, as mentioned in the below diagram, and it consists of 3 categories Red, Green, and Yellow. For each data point, One Hot Encoding will produce a numeric vector of length 3 and its ith value will be 1 representing ith category in the value set - (Red, Green, Yellow). For example, if the data point belongs to Red color, then One Hot Encoded vector would be [1,0,0] and it will be [0,1,0] and [0,0,1] if the data point belongs to Green or Yellow color respectively. The resulting vector can also be converted into multiple columns in the data frame, as shown on the right side of the below diagram.
Issues with One Hot Encoding
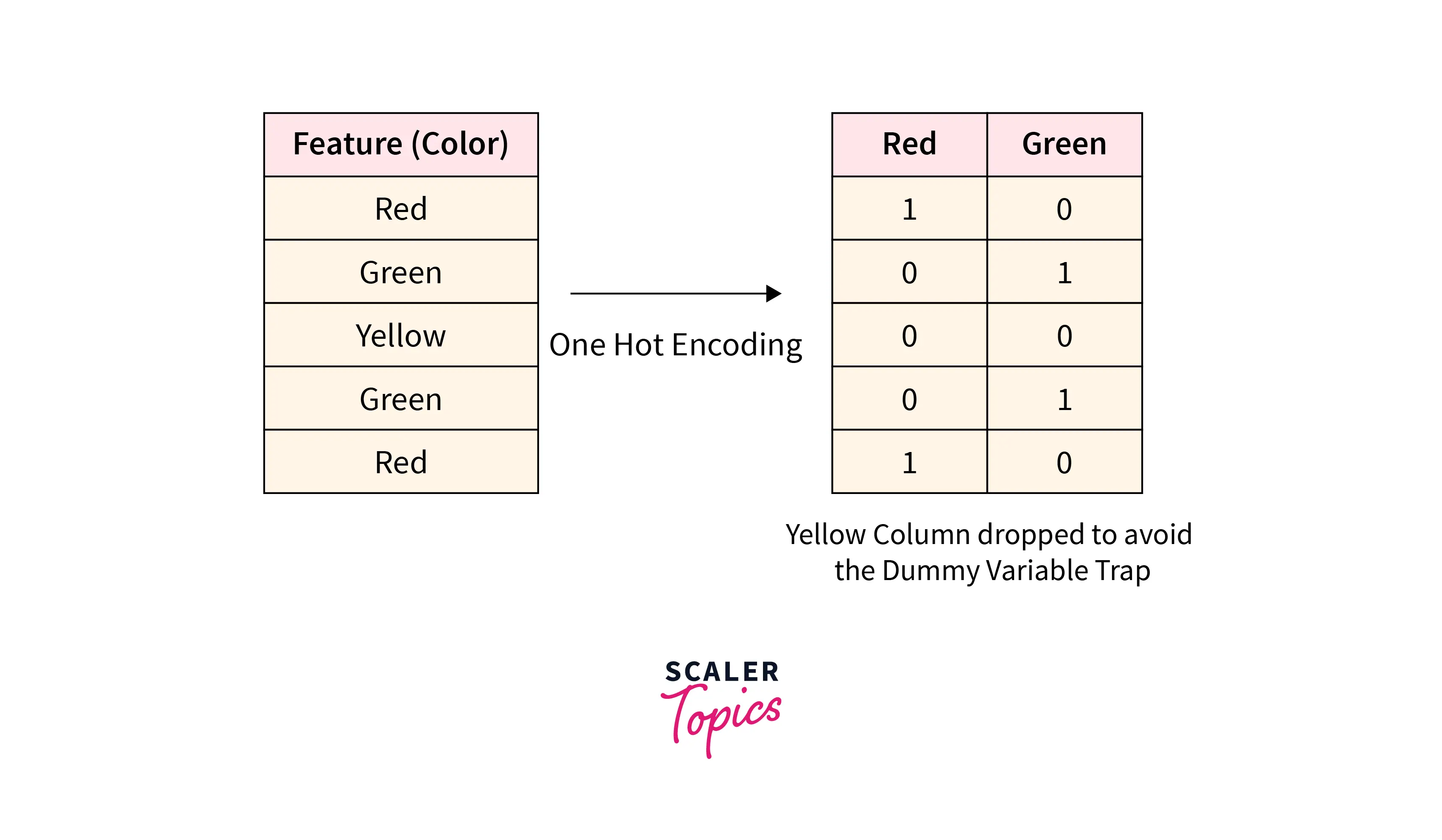
One Hot Encoding process will create new columns/attributes according to the number of categories present in the dataset. These attributes are called Dummy Variables, which are used as a proxy for categorical variables in ML models. This can result in the Dummy Variable Trap scenario, where newly created attributes are highly correlated to each other, and the outcome of one variable can be predicted by using other variables. This leads to multicollinearity, where input features are not independent of each other in a dataset, and it is a serious issue while training various regression models. To avoid the Dummy Variable Trap, we need to drop one dummy variable. So when One Hot Encoding produces n new columns/attributes, we can just use n-1 columns by dropping one redundant column. For example, in the above diagram, we can remove the Yellow column as it can be predicted by other columns. It is a redundant column, as we know that Yellow columns will have a 1 value when Red and Green columns are 0. So by dropping it, we can avoid the Dummy Variable Trap without affecting model accuracy.
When to Use One Hot Encoding
One Hot Encoding should be used when -
- The categorical features in the dataset are not ordinal, i.e., there is no natural ordering to their categories.
- If the number of categories present in the dataset is less, the resulting vector will not suffer from the curse of dimensionality and multicollinearity.
How to Convert Categorical Data to Numerical Data
There are many ways to convert/encode categorical data into numerical format, although the most common methods are -
- Integer Encoding
- One Hot Encoding
- Learned Embedding
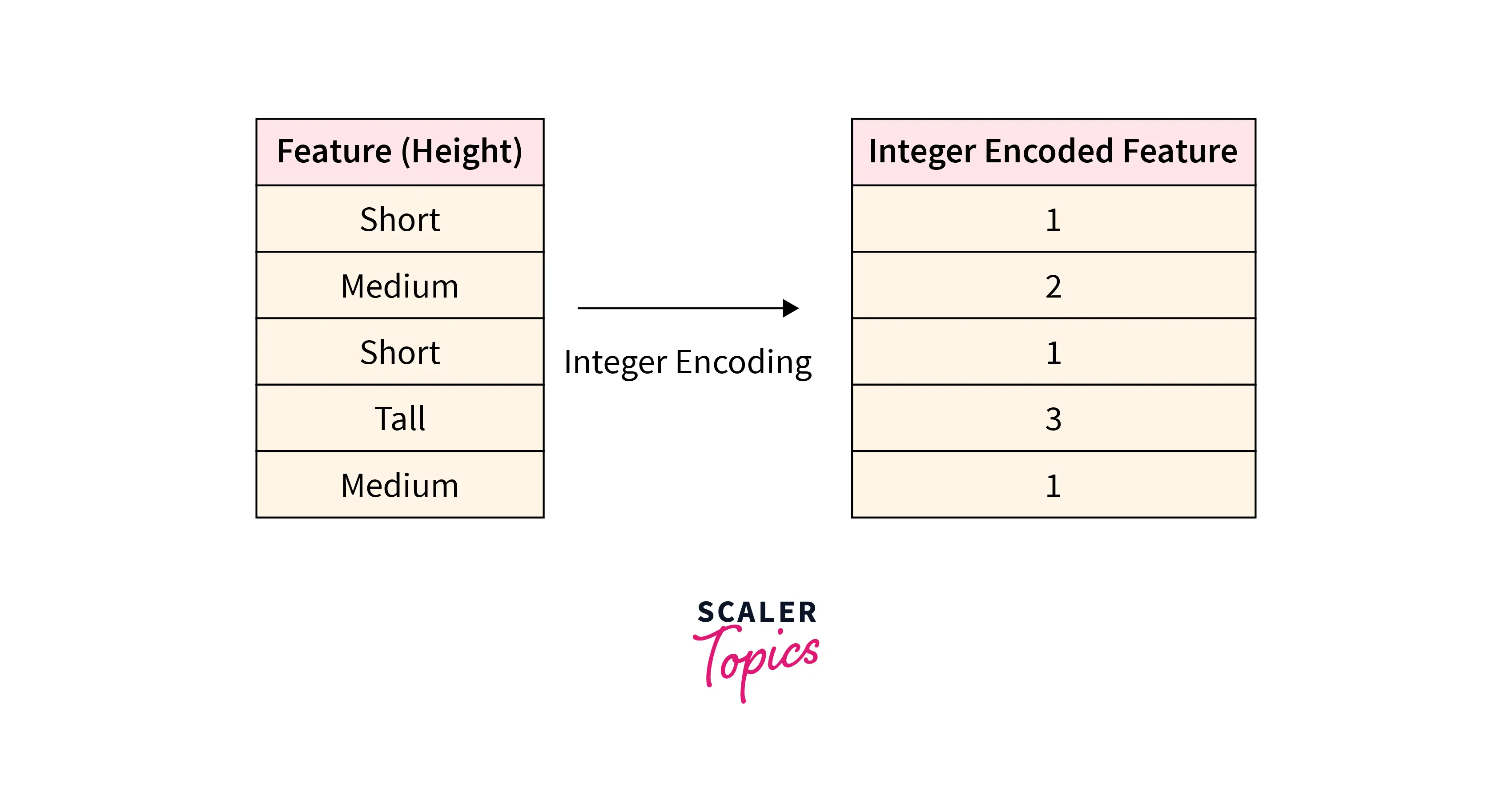
Integer coding is used to convert ordinal categorical variables into the numerical format. In this method, each unique category is mapped to an integer to encode a categorical variable for the ML modeling process. For example, if you have one categorical variable, height with categories Short, Medium, and Tall. Using Integer Encoding, this feature height can be encoded by mapping Short, Medium, and Tall to integers 1, 2, and 3 respectively. While mapping the integers to the categories, we need to ensure that the natural ordering of the categories is retained. In the above example, Short (1) < Medium (2) < Tall (3) will retain the natural ordering of the variable.
One Hot Encoding is used to encode nominal categorical variables. As explained in the previous section, in this method, a categorical variable is mapped to a binary vector with a length equal to the number of categories present in the feature.
Learned Embedding is a distributed representation of categorical data. In this method, each category is mapped to a distinct vector which is learned by training a neural network. This method ensures that ordinal relationships of the categories are retained in a way that related categories can be clustered together. A few examples of this method are Word2Vec, Doc2Vec, etc.
Implementation of One Hot Encoding using Python
To implement One Hot Encoding in Python, let’s create a small dataframe representing a list of cars.
One Hot Encoding using Pandas
Pandas library in Python provides get_dummies function to perform One Hot Encoding on the categorical variable in a dataframe. It takes the following parameters -
- data - It is the input data containing categorical variables. It can be an array, series, or dataframe.
- columns - List of columns to be encoded using One Hot Encoding
- prefix - It is a single string or list of strings that will be used as a prefix when creating new columns after One Hot Encoding.
- drop_first - It is a boolean parameter that is used to remove the first dummy variable
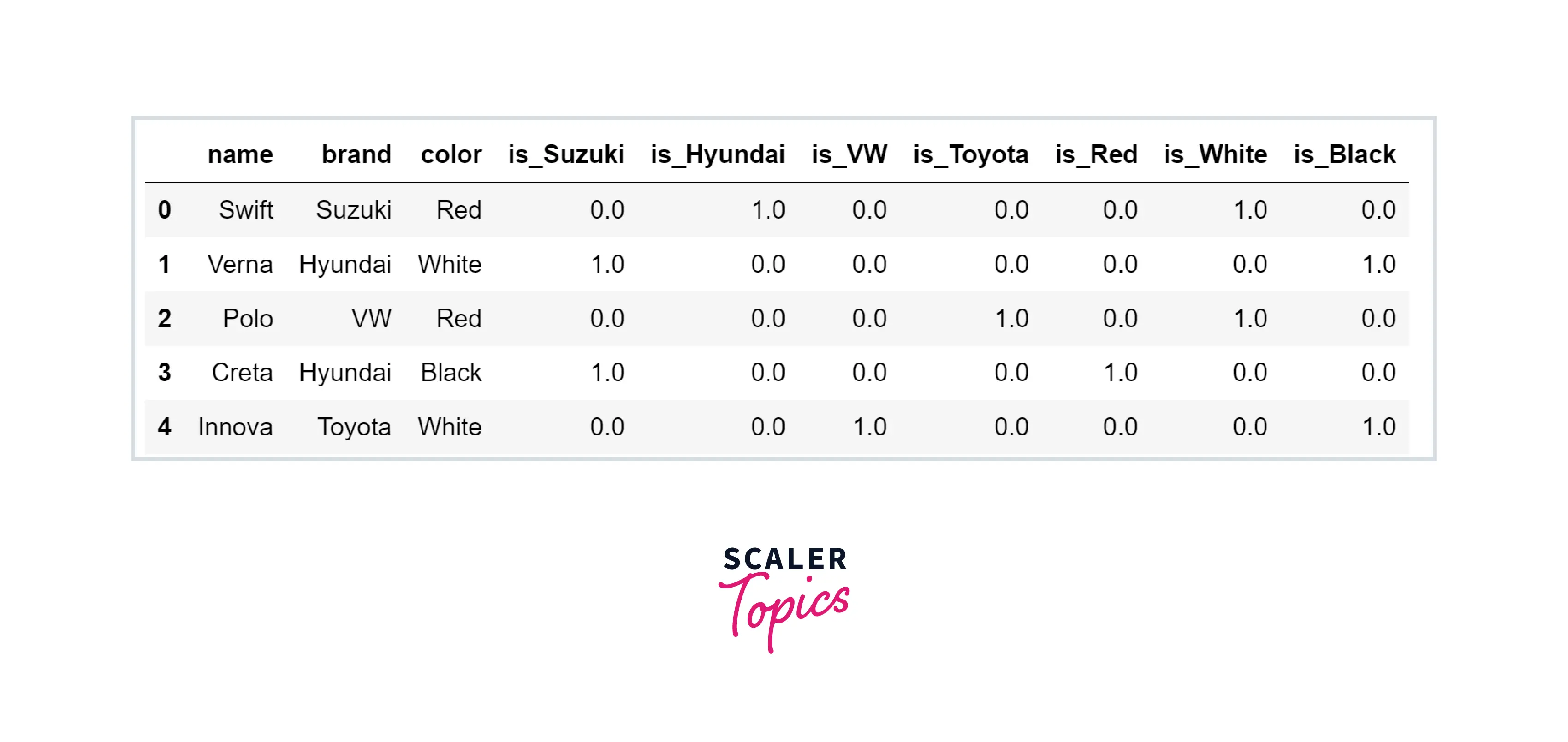
Output:
As you can see in the above implementation, that features brand and color were encoded, and new columns were created with the prefix is.
One Hot Encoding using Scikit-Learn
The scikit-learn library also provides OneHotEncoder class which takes an array of integers or strings and converts them to One Hot Encoded binary vector.
Conclusion
- One Hot Encoding is a technique that is used to convert categorical variables into numerical format. It maps a categorical variable to a binary vector with a length equal to the number of categories present in the variable.
- One Hot Encoding suffers from Dummy Variable Trap, and we can avoid it by dropping one dummy variable.
- One Hot Encoding can be implemented in Python using Pandas or Scikit-learn library.