What is Web Scraping? | How to Extract Data?
Learn via video course

Overview
Web Scraping can be defined as a process of extracting content and data from the Internet. It provides automated methods to quickly scrape large amounts of data from websites or the Internet.
Scope
- This article describes Web Scraping, its use cases, and the different kinds of Web Scrapers.
- This article also describes how Web Scraping works and provides an example of how it can be implemented using the BeautifulSoup library in Python.
What Is Web Scraping
The amount of data we are generating is growing at an exponential rate. While this data has many sources, its most extensive repositories are Websites and the Internet. The method to extract this data from websites is called Web Scraping.
Suppose you want some information about Mahatma Gandhi from Wikipedia or any other website, you can extract this data by copying and pasting the information into your file. But if you want this information for hundreds of different personalities, manually getting this data is impossible, and you need an automated and efficient method to scrape all of this information quickly. And here, Web Scraping comes into the picture. Web Scraping can be defined as an automated process to extract content or data from the Internet. It provides various intelligent and automated methods to quickly extract large volumes of data from websites. Most of this data will be in unstructured or HTML format, which can be further parsed and converted into a structured format for further analysis. In theory, you can scrape any data on the Internet. The most common data types scraped include text, images, videos, pricing, reviews, product information, etc.
There are many ways you can perform Web Scraping to collect data from websites. You can use online Web Scraping services or APIsor create your own custom-built code to scrape the information. Many popular websites such as Google, Twitter, Facebook, etc. provide APIs that allow the collection of the required data directly in a structured format.
What Is Web Scraping Used For?
Web Scraping has countless applications across industries. A few of the most common use cases of Web Scraping include -
Price Monitoring
- Organizations scrape the pricing and other related information for their and competitors' products to analyze and fix optimal pricing for the products to maximize revenue.
Market Research
- Organizations use Web Scraping to extract product data, reviews, and other relevant information to perform sentiment analysis, consumer trends, and competitor analysis.
News Monitoring
- Organizations dependent on daily news for their day-to-day functioning can use Web Scraping to generate reports based on the daily news.
Sentiment Analysis
- Companies can collect product-related data from Social Media such as Facebook, Twitter, etc., and other online forums to analyze the general sentiment for their products among consumers.
Contact Scraping
- Organizations scrape websites to collect contact information such as email IDs, and mobile numbers to send bulk promotional and marketing emails and SMS.
Other than the above use cases, Web Scraping can also be used for numerous other scenarios such as Weather Forecasting, Sports Analytics, Real Estate Listings, etc.
How Web Scrapers Work?
In general, to extract data from websites, Web Scraping methods follow three steps as mentioned below -
- Make an HTTP Request to The Website URLs - In the first step, you need to provide a list of URLs to the Web Scrapers from which you want to extract the data and it will make HTTP requests to these URLs.
- Load and Parse the Websites Code - Once the HTTP request is successfully executed to the URLs mentioned in the first step, Web Scrapers can load the HTML or XML code of the websites. Some Web Scrapers can also load CSS or JavaScript elements as well. Further, Web Scraper will parse the HTML code to identify and extract relevant data which is predefined by you.
- Save Relevant Data Locally - Once all relevant data is extracted, Web Scrapers can store the data in a structured format, usually as an Excel Spreadsheet or CSV file. These scrapers can also save the data in other formats, such as JSON, etc.
Different Types of Web Scrapers
Web Scrapers can be categorized based on various factors, including Self-built or Pre-built Web Scraper, Browser Extension or Software Web Scrapers, and Local or Cloud Web Scrapers.
Self-Built Web Scrapers require advanced programming knowledge to build and develop. If you want more features, it will require a more advanced understanding of programming languages. Pre-Built Web Scrapers can be downloaded and used directly. Some Scrapers also provide options to customize their features based on your requirements.
Browser Extension Web Scrapers can be added to your browsers. These Scrapers generally have a limited set of features as these are dependent on compatibility with your browser. Software Web Scrapers does not suffer from these limitations as these can be downloaded and installed directly on your computer.
Cloud Web Scrapers run on the cloud and will not use your local computer resources such as RAM, CPU, etc. Local Web Scrapers run on your computer and will consume its resources to perform Web Scraping.
How to Scrape The Web (Step-by-Step)
In this section, we will describe all the steps you need to follow to scrape the websites to extract the required content or data.
Identify the URLs
- In this first step, identify all URLs you want to scrape and extract relevant data for further analysis. For example, you could scrape Amazon's Website to collect product information and customer reviews.
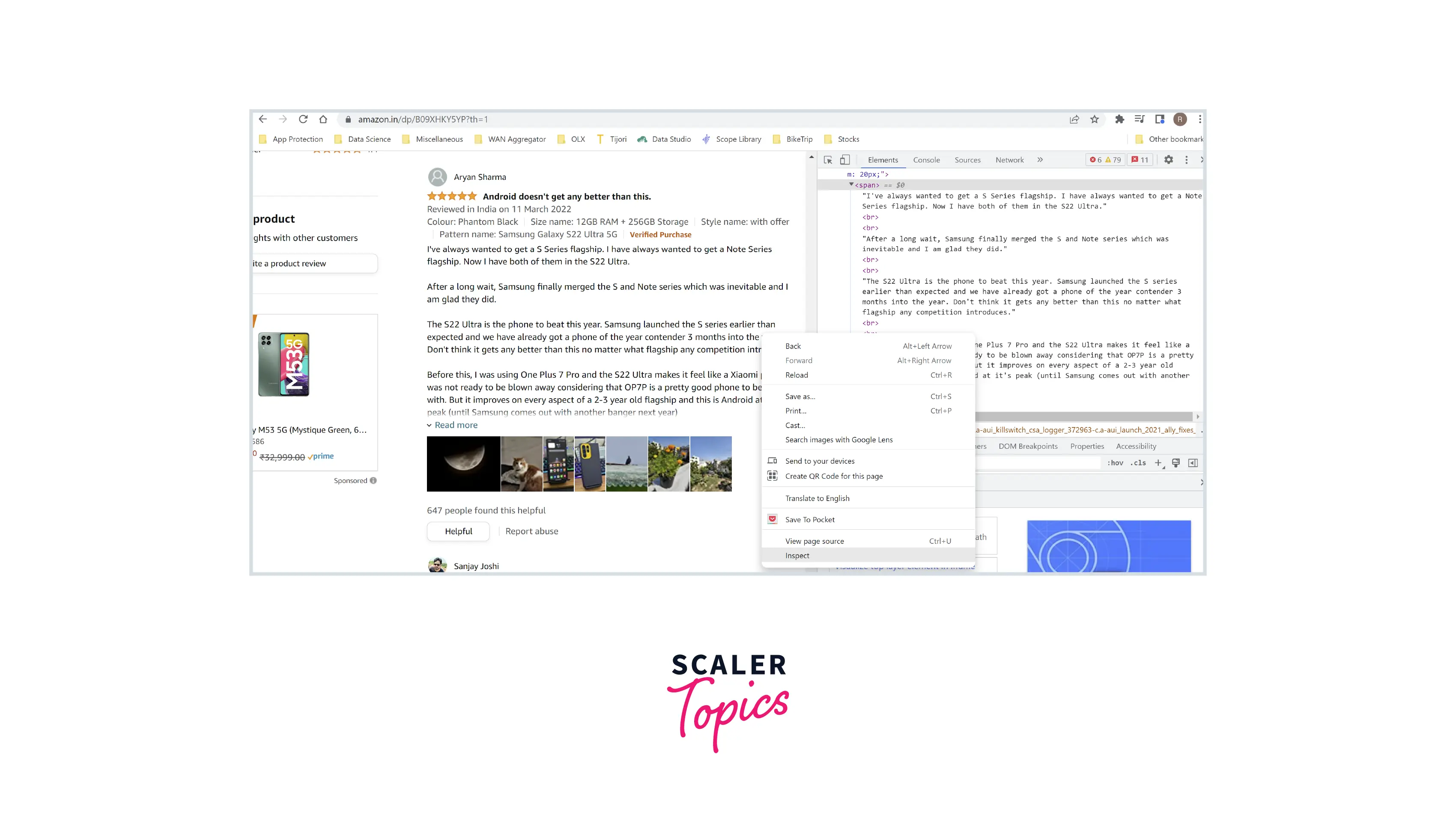
Inspect the Webpage
- Before performing Web Scraping, you need to inspect the Webpage's HTML content. You can do it by right-clicking on the Webpage and selecting Inspect or View Page Source.
Identify the Data You Want to Scrape
- In this step, you need to analyze the Webpage's HTML code to identify the unique HTML tags which contain the relevant data. For example, if you want to scrape the reviews from Amazon, you need to find tags that contain customer reviews, as shown in the below figure.
Write Code for Web Scraping
- Once you have inspected the HTML content of the Webpage and identified all appropriate HTML tags, you can use Python libraries to write your own Web Scraping function. You need to specify what information you want to scrape and parse from the Website.
Code Execution
- In this step, you execute your written code. Then, it will make an HTTP request to the URLs, scrape the data and parse it as mentioned in the previous steps.
Store Final Data
- Once everything required is extracted, the next step is to store this data in a structured format for further analysis. It could be stored locally or in a database in any format, such as CSV, Excel, JSON, etc.
Web Scraping using Beautiful Soup
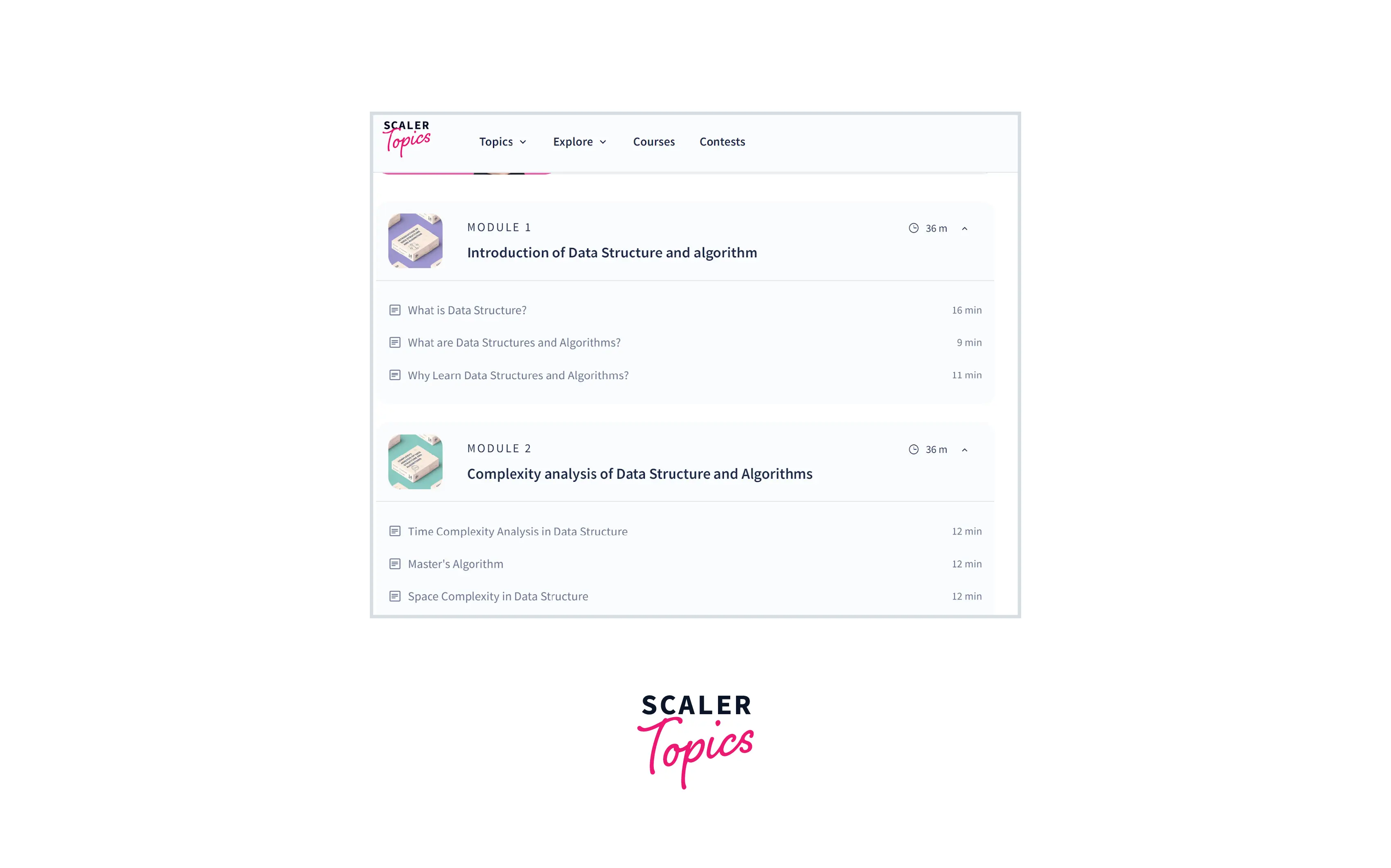
In this section, we will show how you can write a Web Scraper using the BeautifulSoup library provided by Python language. In this example, we will scrape Data Structure Tutorial modules, articles, and other information from this Scaler Topics Webpage as shown in the below figure -
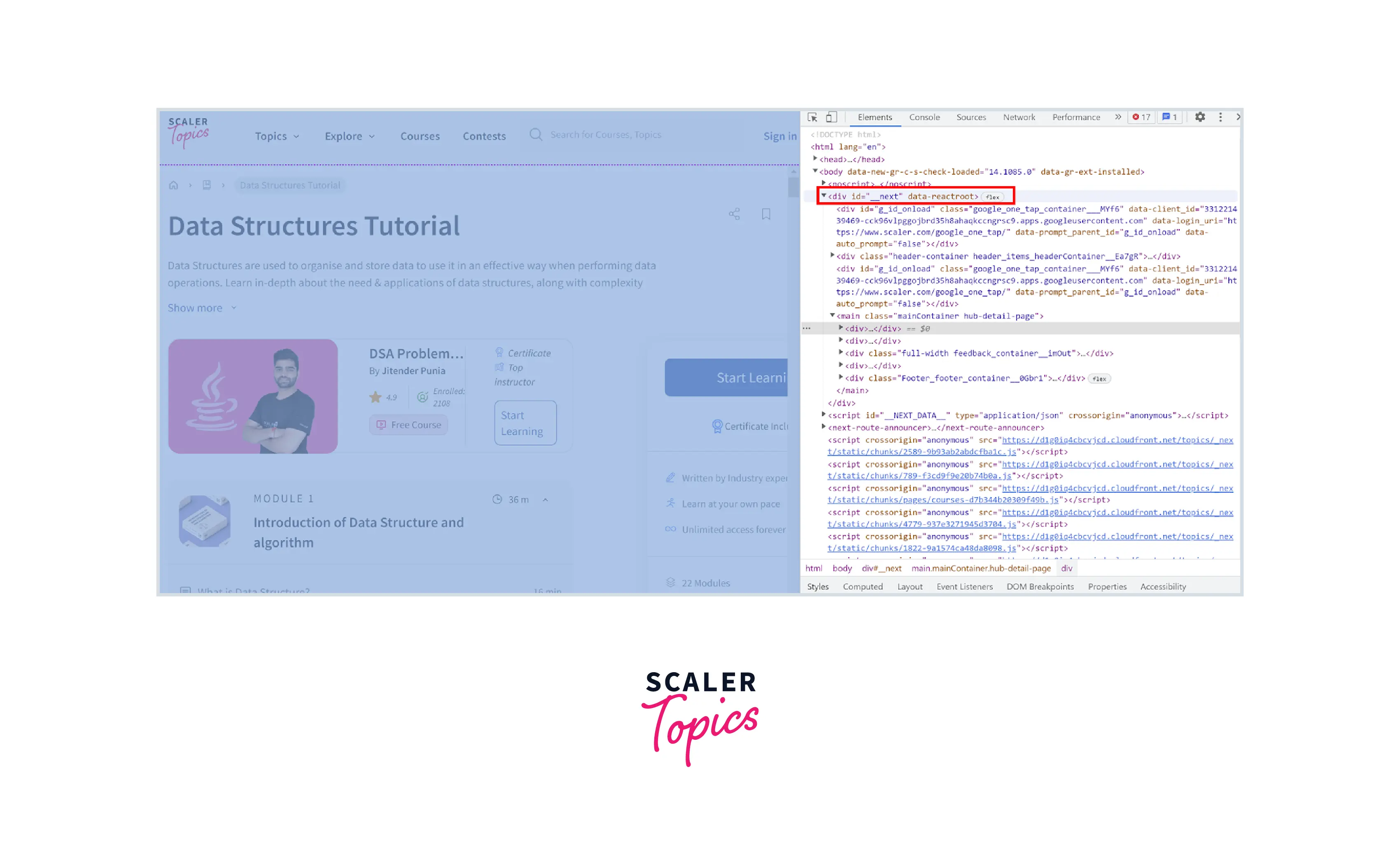
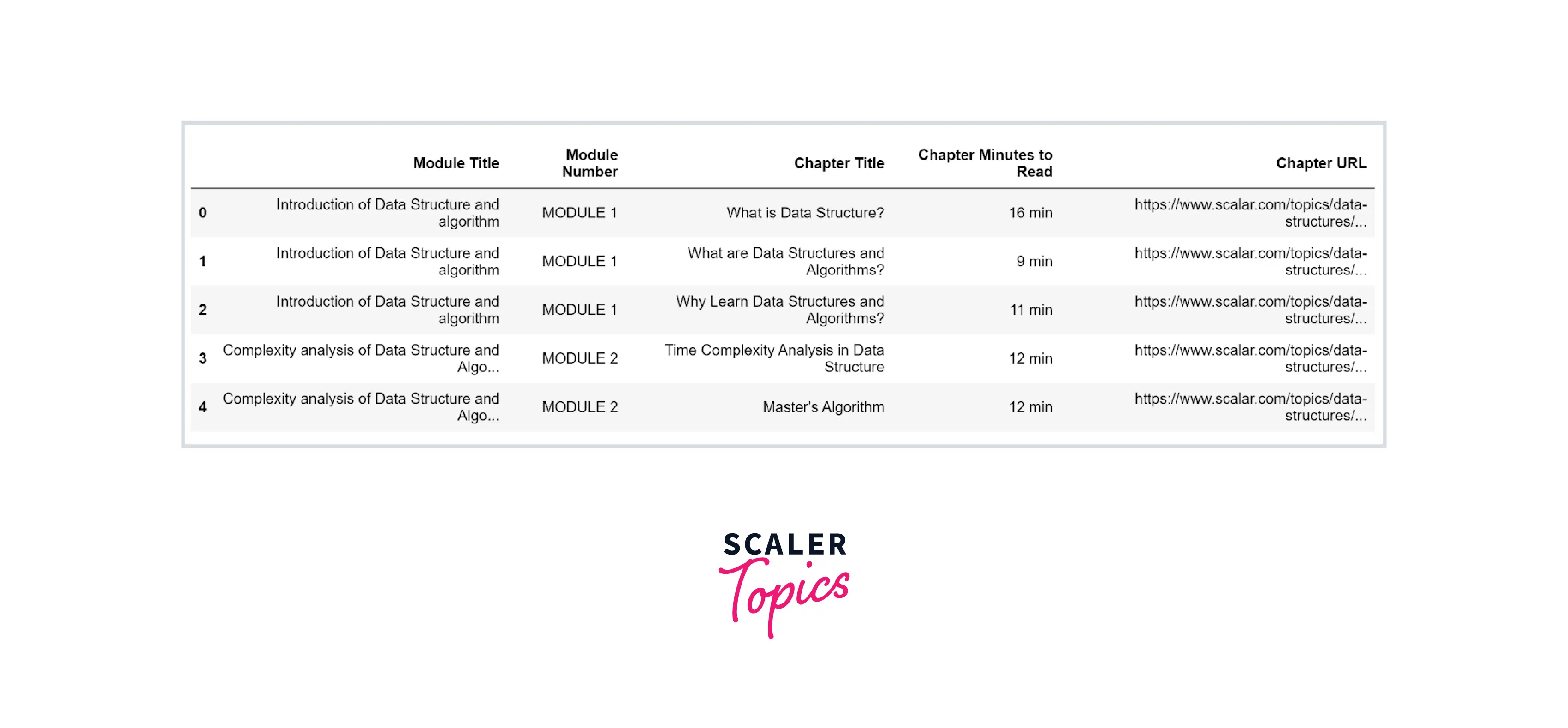
Why Should You Learn It?
In today's digital world, Web Scraping has become an essential skill if you want to make a career in Big Data Analytics. Based on statistics collected from LinkedIn, top industries such as Computer Software, Financial Services, IT Services, Marketing & Advertising, etc. are looking for Web Scraping skills for technical as well as non-technical roles. In addition, Web Scraping is a must-have skill for jobs such as Data Scientists and Data Analysts which are the most paid professionals, and demand for these two profiles is set to grow in the next decade.
Conclusion
- Web Scraping is a technique to extract large amounts of data from the Internet. It has numerous use cases across the industry, such as Price Monitoring, Competitor Analysis, Sentiment Analysis, etc.
- In the Big Data Analytics field, Web Scraping has become an essential skill and is in high demand.
- You can perform Web Scraping through pre-built or software-based Web Scrapers or write your Web Scraping function using the BeautifulSoup library in Python.