Bellman–Ford Algorithm
Learn via video course

Overview
The Bellman-Ford algorithm is an example of Dynamic Programming. It starts with a starting vertex and calculates the distances of other vertices which can be reached by one edge. It then continues to find a path with two edges and so on. The Bellman-Ford algorithm follows the bottom-up approach.
Scope
- This article tells about the working of the Bellman-Ford algorithm.
- Difference between Dijkstra’s and Bellman Ford’s Algorithm.
- Explanation of Bellman Ford Algorithm.
- Complexity of Bellman Ford Algorithm.
Takeaways
- Complexity of Bellman Ford Algorithm
- Time complexity .
Introduction
Suppose that we are going for a picnic, there may be some path leading to the picnic spot where we have to pay taxes and some paths which have houses of our relatives/friends who will give us gifts if we pass by their home. To find the optimal path (path with the least cost) from home to picnic spot we need Bellman Ford Algorithm.
Bellman ford algorithm is used to calculate the shortest paths from a single source vertex to all vertices in the graph.
This algorithm also works on graphs with a negative edge weight cycle (It is a cycle of edges with weights that sums to a negative number), unlike Dijkstra which gives wrong answers for the shortest path between two vertices.
Bellman Ford algorithm is easier to implement when compared to dijkstra algorithm and optimal for distributed systems. (but on the other hand, it has a high time complexity i.e. where V and E are numbers of vertices and edges respectively.
Example of Bellman Ford Algorithm
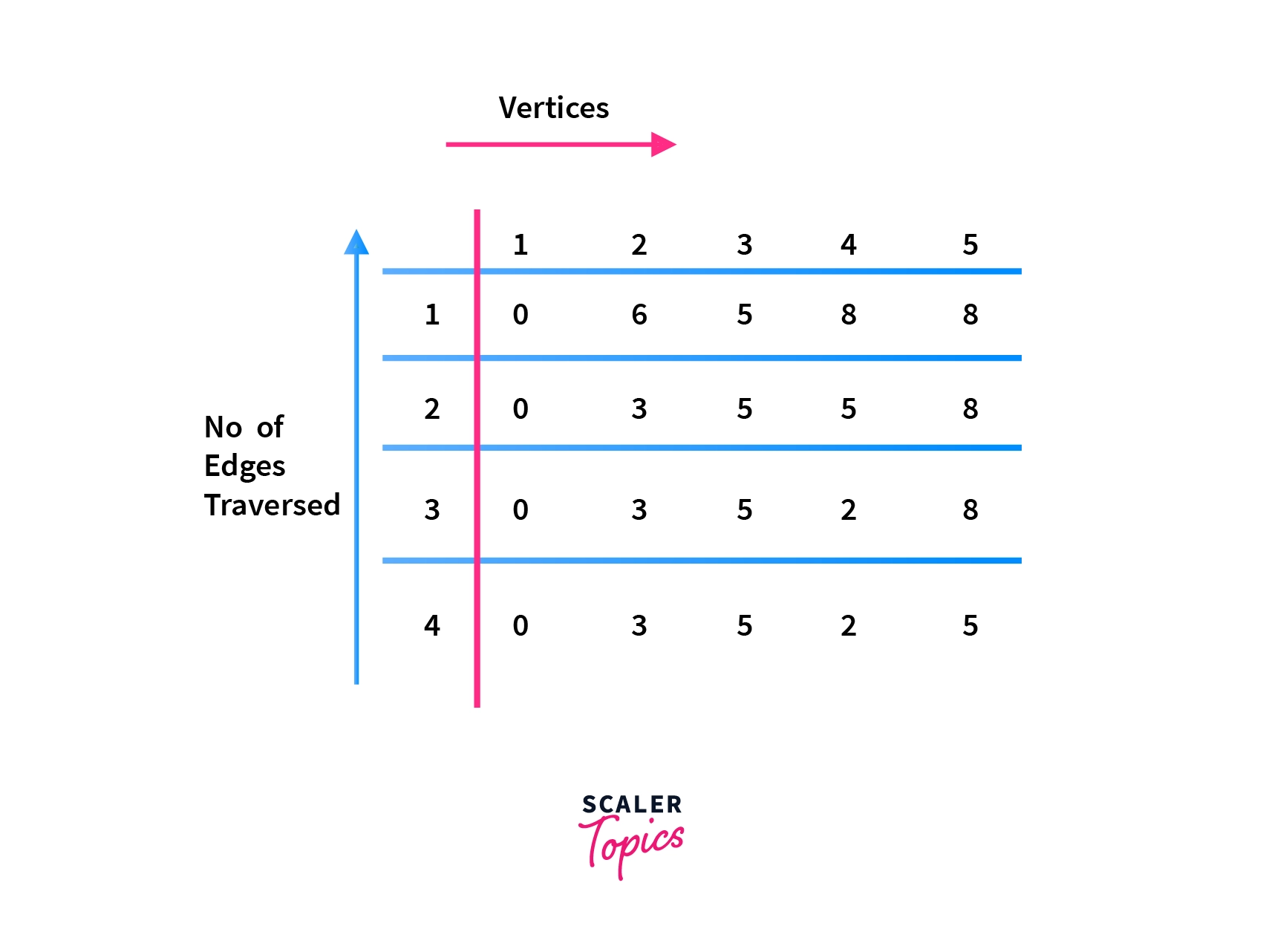
Suppose that we have a graph consisting of 5 vertices having edges between them as shown in the picture below. Now, we want to find shortest distance to each vertex vi 0<i<6 starting from the vertex 1.

After performing bellman ford algorithm on the above graph the output array would look like - Shortest_Distance = [0, 3, 5, 2, 5]
Where each index 'í' of array denotes the shortest distance of the ith vertex from 1st vertex, 1<=i<=5.
How Bellman Ford Algorithm Works?
The algorithm works by iteratively relaxing the edges of the graph to find the shortest path.
Here are the step-by-step workings of the Bellman-Ford algorithm:
Step 1: Initialize distances and predecessors
The algorithm starts by initializing the distance of the source node to 0 and the distances of all other nodes in the graph to infinity.
Step 2: Relax edges
The algorithm then iteratively relaxes the edges of the graph. For each edge u→v with weight w, it checks if the distance to v can be improved by going through u. If the distance can be improved, it updates the distance of v and sets its predecessor to u.
Above step is repeated V-1 times for every edge.
Step 3: Check for negative cycles
After all the edges have been relaxed, the algorithm checks for negative cycles in the graph. A negative cycle is a cycle whose total weight is negative. If there is a negative cycle in the graph, the algorithm reports it and terminates. Step 2 (relax edges) is repeated one more time for all the edges. If there is some edge some which can be further relaxed then we say that there is an negative cycle present in the graph.
Step 4: Shortest paths
If there are no negative cycles in the graph, the algorithm returns the shortest path from the source node to every other node in the graph.
Input:
- A 2D Array/List denoting edges and their respective weights.
- A src vertex.
Output: An array where each index denotes the shortest path length between that vertex and src vertex.
Procedure:
-
In this step, we would declare an array of size V(Number of vertexes) say dis[] and initialize with all of its indexes with a very big Value (preferably INT_MAX) except src which will be initialized with value 0. We are doing this because initially we assume that it takes infinite time to reach any of the vertices from our source vertex and we are initializing dis[src]=0 because we are already on source vertex.
-
In this step, the shortest distance is calculated. For it, we would do the underlying step V-1 times. For every edge u→v make dis[v]=min(dis[u]+ wt of edge u→v, dis[v]) It means whenever we are on any vertex u we will check if we can reach any of its neighbors in less time it is currently possible to visit, we will update the dis[v] to dis[u]+wt of edge u→v.
-
In this step, we will check if there exists a negative edge weight cycle traversing each and every edge u→v and checking if there exists dis[u] + wt of edge u→v < dis[v] then our graph contains a negative edge weight cycle because traversing the edges again and again is beneficial as it is lowering the cost to traverse the graph. --> :::
Explanation of Bellman Ford Example
Difference between Dijkstra's and Bellman Ford's Algorithm
| Bellman Ford Algorithm | Dijkstra Algorithm |
|---|---|
| Its implementation is inspired by the dynamic programming approach. | Its implementation is inspired by the greedy approach. |
| It is easier to implement in a distributive way. | It is quite complex to implement in a distributed way. |
| It also works when the given graph contains a negative edge weight cycle. | It fails if a graph contains a negative edge weight cycle. |
| It's is more time consuming than Dijkstra's. It's Time complexity is O(VE) | It's Time complexity is O(ELogV) |
Pesudocode
Codes Implementation of Bellman Ford Algorithm
-
C/C++ Implementation of Bellman Ford
-
Java Implementation of Bellman Ford
-
Python Implementation of Bellman Ford
Complexity Analysis of Bellman Ford
Time Complexity -
Since we are traversing all the edges V-1 times, and each time we are traversing all the E vertices, therefore the time complexity is O(V.E).
Space Complexity -
Since we are using an auxiliary array dis of size V, the space complexity is O(V).
Where V and E are numbers of vertices and edges respectively.
Bonus Tip of Bellman Ford
The algorithm can be speeded up further because in most of the cases we get our final answer after performing step 2 few times only. Because dis array stops getting updated after some steps, So traversing edges again and again is nothing but waste of time.
To check wether any value of dis gets updated in any given iteration, we can keep a flag in the outer loop of Step 2 and if it not changed in the inner for loop then we can exit from the loop becuase we have already got our answer.
Though the modification will not change the asymptotic nature of the algorithm because in some graphs we will need all the V-1 steps to be done. But it will optmize the run time of algorithm in a "average case" i.e. random graphs.
The minor modification need to be done in step 2 is given below -
Though the average case Time Complexity would be - O(V.E) but in the best case it can be done in only O(E) time. Think of the case in which we get out of the loop after the very first or second step.
Applications
- Checking for negative edge weight cycle.
- For finding shortest path of all vertices from single source.
- Routing Algorithms.
Conclusion
- In this blog, we have discussed one of the most important graph algorithms i.e. Bellman-Ford algorithm which is used to find the shortest path to all vertices from a single source vertex in O(VE) time complexity.
- It can find shortest distance of all vertices from single source. It can also detect if there exists a negative edge weight cycle in the given graph. Therefore, it also finds its way in many routing techniques.
- If you want to upskill yourself in Data Structures and algorithms then do checkout, Scaler where you will get live lectures, assignments, and regular tests from the people working in your dream company.