Trie Data Structure
Learn via video course

Overview
Trie data structure is an advanced data structure used for storing and searching strings efficiently. Trie comes from the word reTRIEval which means to find or get something back. Dictionaries can be implemented efficiently using a Trie data structure and Tries are also used for the autocomplete features that we see in the search engines. Trie data structure is faster than binary search trees and hash tables for storing and retrieving data. Trie data structure is also known as a Prefix Tree or a Digital Tree. We can do prefix-based searching easily with the help of a Trie.
Scope of Article
- This article defines a Trie data structure and explains the intuitive logic of the data structure.
- We learn to implement the insert, search and delete operation in a Trie.
- We learn the applications of a Trie along with the advantages and disadvantages of using Trie data structure.
- Finally, we discuss the entire implementation of a Trie data structure along with its code.
Takeaways
- Time complexity of insertion, deletion and searching for a string of length 'k' in the Trie data structure is:
- Insert - O(k)
- Delete - O(k)
- Search - O(k)
- The time complexity for building a Trie data structure is O(N * avgL), where 'N' is the number of strings we want to insert in Trie and 'avgL' is the average length of 'N' strings.
- Trie data structure has many applications, including 'prefix-based searching', 'sorting strings lexicographically' etc.
What is a Trie Data Structure?
Trie data structure is a tree-based data structure used for storing collections of strings. The word trie comes from the word reTRIEval which means to find or get something back. If two strings have a common prefix then they will have the same ancestor in the trie. In a trie data structure, we can store a large number of strings and can do search operations on it in an efficient way. A trie can be used to sort a collection of strings alphabetically as well as search whether a string with a given prefix is present in the trie or not. A dictionary can be implemented efficiently with the help of a trie data structure. Let us now discuss the when and how to implement a Trie Data Structure.
Why Use a Trie Data Structure?
A trie data structure is used for storing and retrieval of data. Another data structure that we can think of for doing the same operations is a Hash Table. However, a trie data structure can be used to handle these operations more efficiently than a Hash Table. Moreover, a trie data structure can be used for prefix-based searching while we can not use a hash table for the same. An example of prefix-based searching is to search how many strings present in a collection of strings contain a given prefix. A trie data structure gives us advantages over a hash table mainly in the following factors-
- A trie data structure can be used to implement a wide range of features that can't be implemented with a hash table. For example, Prefix-based searching can't be done with a hash table.
- There are no collisions in a trie data structure which means a better worst-case time complexity than a hash table that is not implemented properly.
- Hash functions are not used in a Trie data structure.
- Searching of a string in a Trie data structure is done in O(k) time complexity. Where k is the number of words in the query string. It may also take less than O(k) time when the query string is not present in the trie.
Properties of a Trie Data Structure
The structure of a trie is like that of a tree. Each trie consists of a root node. The root node branches into various child nodes having multiple edges. Each TrieNode consists of an array of pointers where every index of the array represents a character. Each node of a trie represents a string and each edge represents a character. The root node is an empty string. Each node except the root node is a string having characters along the path from the root to that node. Let us understand the structure of the Trie data structure with the help of an example.
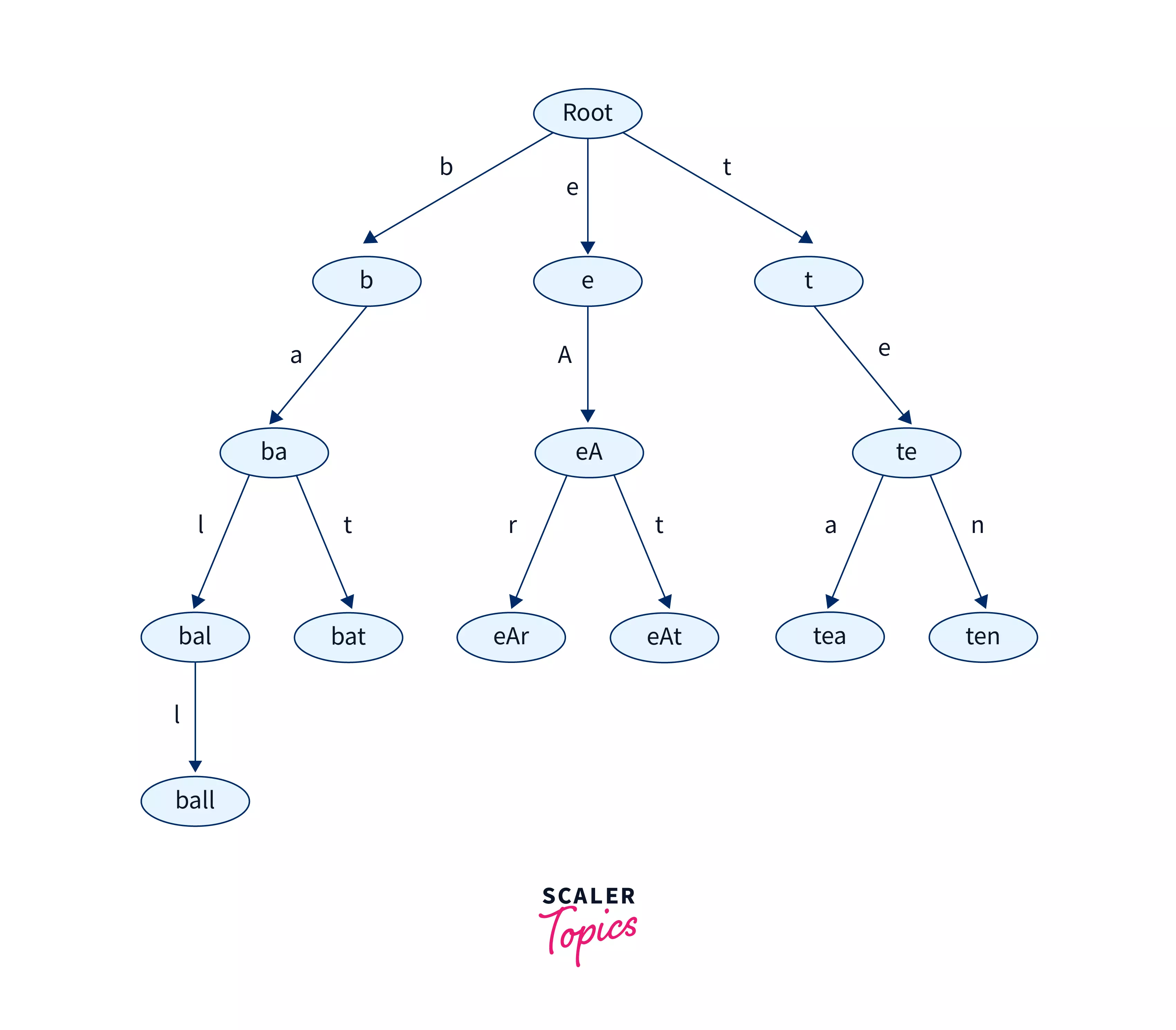
The diagram above shows a trie data structure with input strings as ball, bat, eAr, eAt, tea, and ten. We can see that every node represents a part or prefix of the given strings. The root node represents an empty string. Each edge is represented by a character.
Every level of the Trie data structure represents a prefix of a given length. If we consider the root node to be at level 0. Then the root node represents a prefix of length 0 or an empty string. Level 1 of the Trie represents a prefix of length 1 and so on.
Two child nodes have the same ancestors if tea and ten have the same ancestors which are te and t. This is because they share the same prefix of te.
Note that we can include any number of characters in our Trie data structure ranging from alphabets, numbers, and special characters. In this article, we will discuss strings with characters a-z. Thus for every node in the Trie, we will need an array of pointers of size 26. Where the 0th index will represent a and the 25th index will represent z.
Another important thing to note is that every string in the Trie data structure is sorted lexicographically from left to right. We will learn how to implement it while discussing the insert operation in a Trie.
Now let us discuss how we can implement insert, search and delete operations in a Trie data structure.
Basic Operations in a Trie Data Structure.
In this section, we will discuss the logic behind the insert, search and delete operations in a Trie data structure. We will understand the codes for each of the operations one by one and then implement the entire code for Trie data structure in the latter part of the article.
Insert Operation in a Trie.
With the help of the insert operation, we can insert new strings into the Trie data structure. Let us first understand the structure of a Trie node. As we are considering strings with character a-z. Every Trie node will have a character pointer array of size 26. . We will create the structure of a TrieNode as follows-
- Each TrieNode will have 26 children from a-z represented by a character pointer array.
- Each node will have a wordEndCnt integer variable. This variable will store the count of the strings in the Trie which are the same as that of the prefix represented by that node of the Trie.
- Inside the structure of a TrieNode we made a constructor TrieNode() which will initialize every index of the childNode pointer array with NULL whenever a new node is created. It will also initialize the wordEndCnt value for every node with 0.
Before inserting any string into the Trie we create a root node for the Trie. The structure of the root node will be as follows.
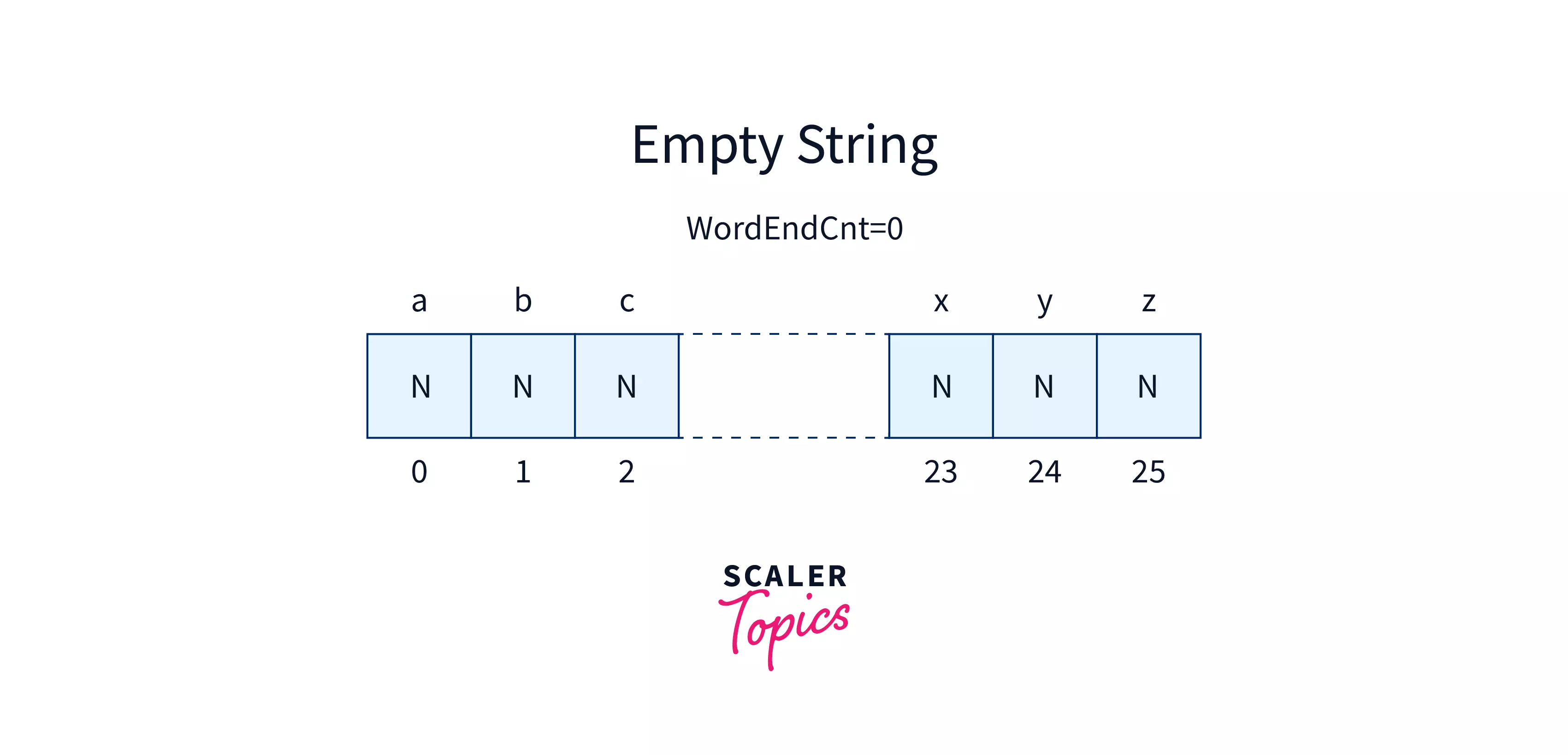
The root consists of an empty string and 26 pointers each initialized with NULL. N in the diagram represents a NULL value at every index. Now let us try to insert the string tea in the Trie.
Insert operation : "tea"
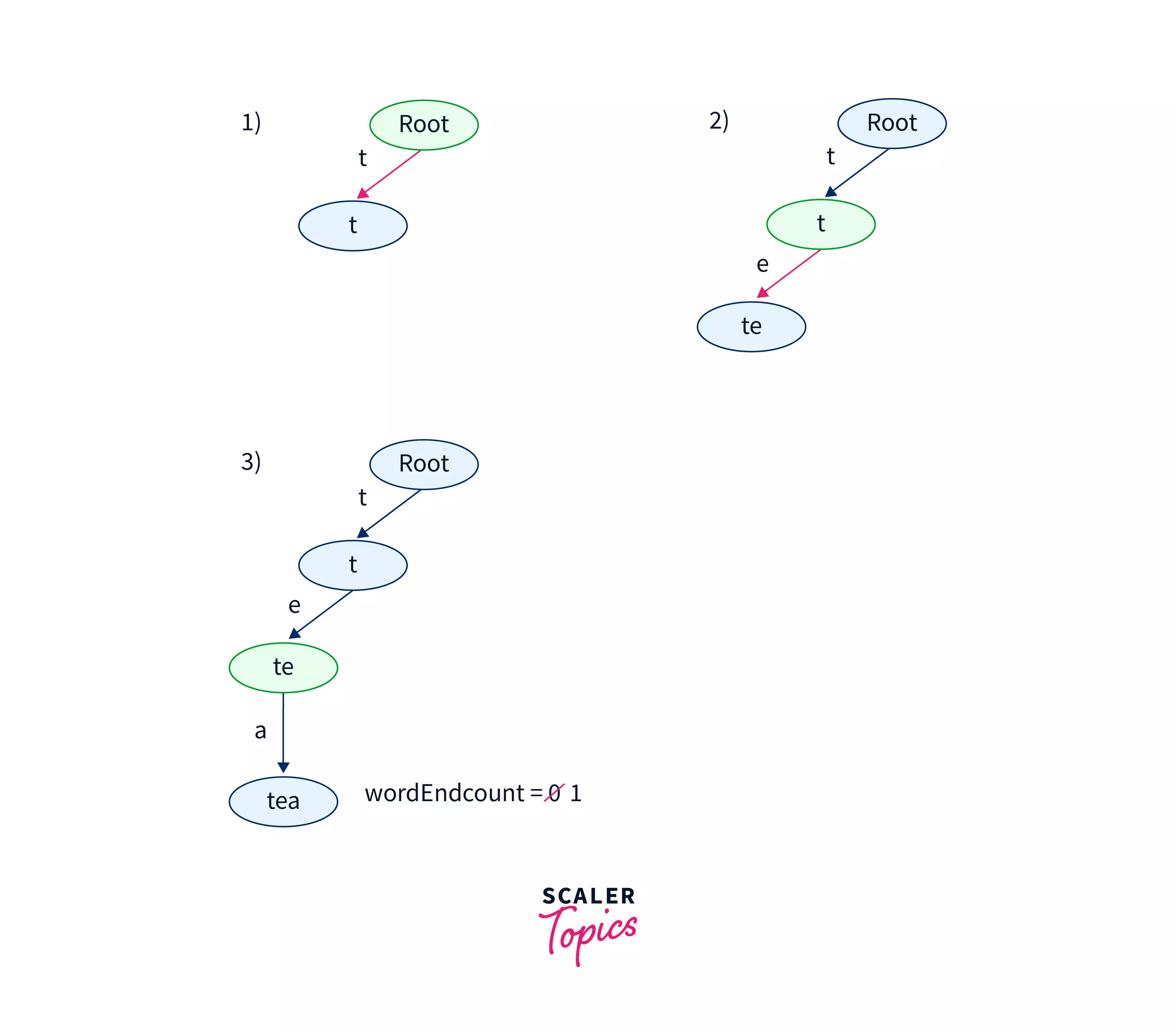
The diagram above shows the steps for insertion of the string tea in the Trie. In every step, the node in which the operations are done is marked with green. We will refer to this node as the current node.
- The root node was created. Every index of the childNode pointer array is NULL. The current node initially will be the root node. The first character of the input string is t. In the root node, we will check whether the t-a th index of the childNode array is NULL or not. As the t-a th index of the childNode array is NULL. We make a new TrieNode with help of the constructor defined in the structure of the TrieNode. We will point the t-a th index of the childNode pointer array of the root node to the new node created. We will make the new node created as the current node and proceed to the next step. As string t is not the end of the string tea we will not increment the wordEndCnt variable for the current node or the new node created in step 1.
- In step 2 we will follow the same steps as in step 1. The second character of the input string is e. In the current node, we will check whether the e-a th index of the NULL or not. As e-a th index of the childNode array is NULL we will again create a new node. We will point the e-a th index of the current node to the newly created node. We will make the new node as current and proceed to the next step. As the string te is not the end of the string tea we will not increment the wordEndCnt value for this node.
- In step 3 we will move to the third character of the input string, i.e a. We will check whether the a-a th index or the 0th index of the childNode pointer array is null or not. As it is NULL we will make a new node and do the same steps as in steps 1 and 2. We will make the new node the current node. However, as the string tea is the end of the string tea we will increment the wordEndCnt value for this node.
Insert operation : "ten"
Now let us try to insert the string ten in the same trie. The steps for insertion are shown in the diagram below.
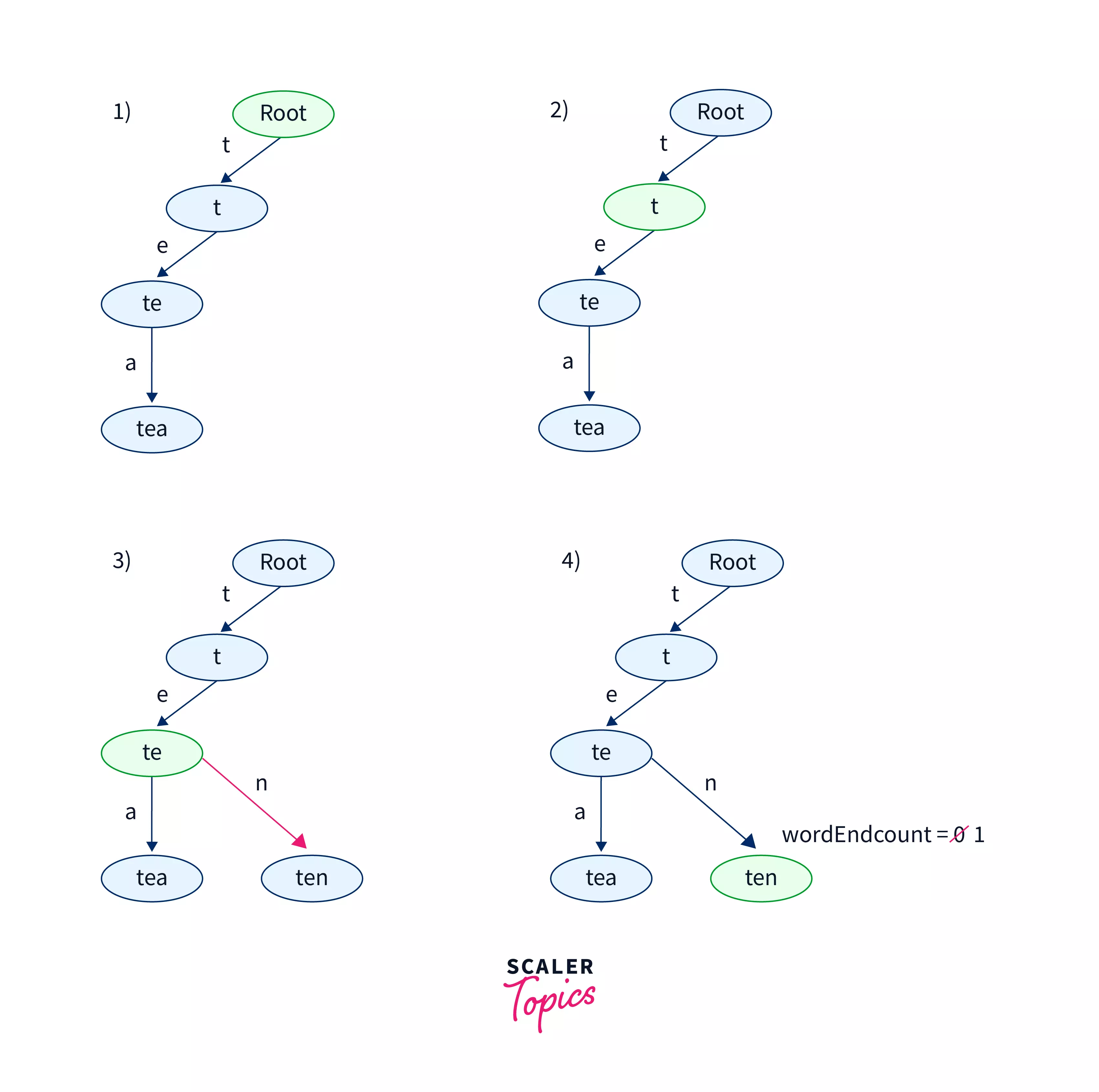
- Initially, the current node is the root node. The first character of the input string is t. As the t-a th index of the childNode pointer array is not NULL we will not create a new node. The current node is shifted from the root node to the node pointed by t-a th index of the childNode pointer array of the root node
- Now we check for the second character of the input string,i.e e. As the e-a th index of the current node is also not null we shift the current node to the node pointed by e-a th index of the current node.
- Now we check for the last character of the input string, i.e n. As the n-a th index of the current node is NULL we make a new node and follow the same steps as discussed above. We increment the wordEndCnt variable for this node as this character is the last character of the input string.
Implementation of the Insert function in Trie data structure
Let's define a function insert_key(TrieNode *root,string &key) which will take two parameters. The first parameter is the root of the Trie. The second parameter is a string that we want to insert in the Trie data structure. We make a currentNode pointer and initialize it with the root node. Then we loop across the entire length of the string key and follow the algorithm discussed above. Finally return the updated root node from the insert_key() function.
C++ Implementation
Search Operation in Trie Data Structure
With the help of the search operation, we can search whether a string is present in the Trie data structure or not. The search operation can be modified to use in different ways. In this article, we will discuss the search operation to check whether the entire string given in the query function is present in the Trie data structure or not. If the query string is present we will return boolean true else we will return boolean false.
The search operation in a Trie data structure is similar to that of an Insert operation. The only difference in a Search operation is that whenever we find a node having X-a th index of childNode pointer array of the current node as NULL we return false instead of making a new node. Here X can be any character of the query string. We return True only when we process the entire query string without coming across a null pointer and wordEndCnt for the last node is greater than 0.
We will use the same Trie obtained after the second insert operation discussed above. Let us try to search the string tea in the given Trie.
Search Operation : "tea"
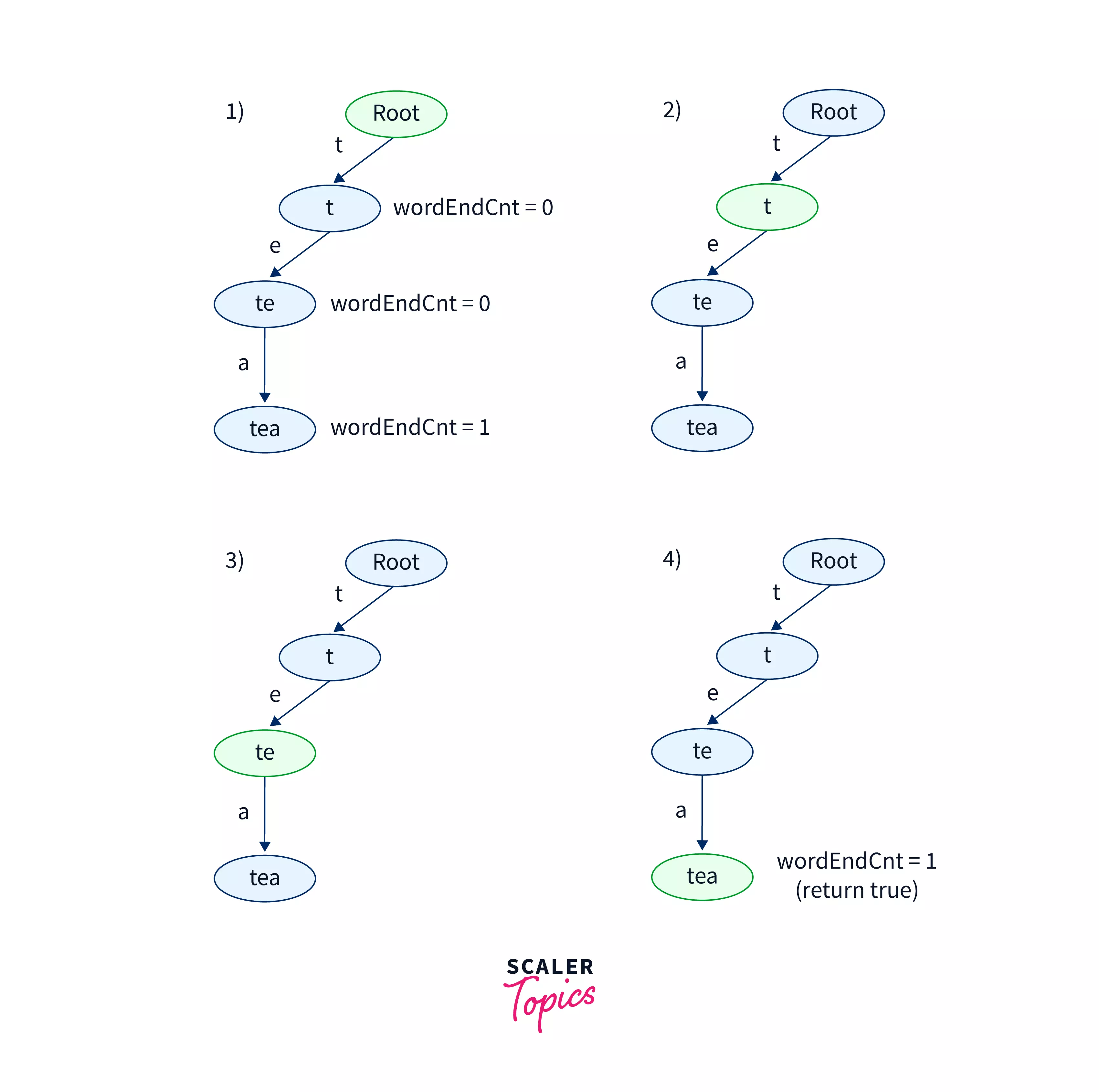
The diagram above shows the steps involved in searching the string tea in the Trie.
-
Initially, the current node is the root node. The first character of the query string is t. We check whether the t-a th index of the childNode pointer array of the current node is NULL or not. As it is not null we move the current node pointer to the node pointed by t-a th index of the current node which is the root node in step 1.
-
Now we check for the second character of the query string i.e e. As the e-a th index of the current node is also not NULL. We move the current node pointer to the node pointed by e-a th index of the current node.
-
Then, we process the last character of the query string, i.e a. As the a-a index of the current node is not equal to null we move the current node pointer to the node pointed by the a-a th index of the childNode pointer array of the current node.
-
Finally, we check if the wordEndCnt for the current node is greater than 0 or not. If the wordEndCnt is greater than 0 which is the case for the query string tea we return true. Otherwise, we return false.
Now let us discuss the case in which the query string is not present in the Trie. Lets us try to search the string to in the Trie.
Search Operation : "to"
- We start with the root node and check for the first character of the query string, i.e t. As the t-a th index is not NULL. We move the current node pointer to the node pointed by the t-a th index of the current node.
- In step 2 we look for the character o in the current node. However, as the o-a th index of the current node is equal to NULL. This means that the query string to is not present in the trie. Thus we return false in this case.
Implementation of the Search Operation in a Trie Data Structure
Let's define a function search_key(TrieNode *root,string &queryString) which will take two parameters. The first parameter is the root of the Trie. The second parameter is a string that we want to search in the Trie. We make a currentNode pointer and initialize it with the root node. Then we loop across the entire length of the string queryString. We return true of we find the queryString in the Trie else we return false.
Delete Operation in Trie Data Structure.
With the help of the delete operation, we can delete the occurrence of a string previously present in the Trie data structure. If a string is not present in the Trie data structure we can't delete that string. If a string is successfully deleted using the delete operation we return boolean True. If the string is not present in Trie then we return boolean false.
To implement the delete operation in a Trie data structure we first search whether the query string is present in the Trie or not. To search the string we apply the same logic discussed in the above section. If the string is not present in the Trie data structure we return false. If the string is present in the Trie data structure we reduce the wordEndCnt for the node pointe by the last current node pointer by 1.
Let us try to delete the string tea from the Trie data structure obtained above.
Delete Operation : "tea"
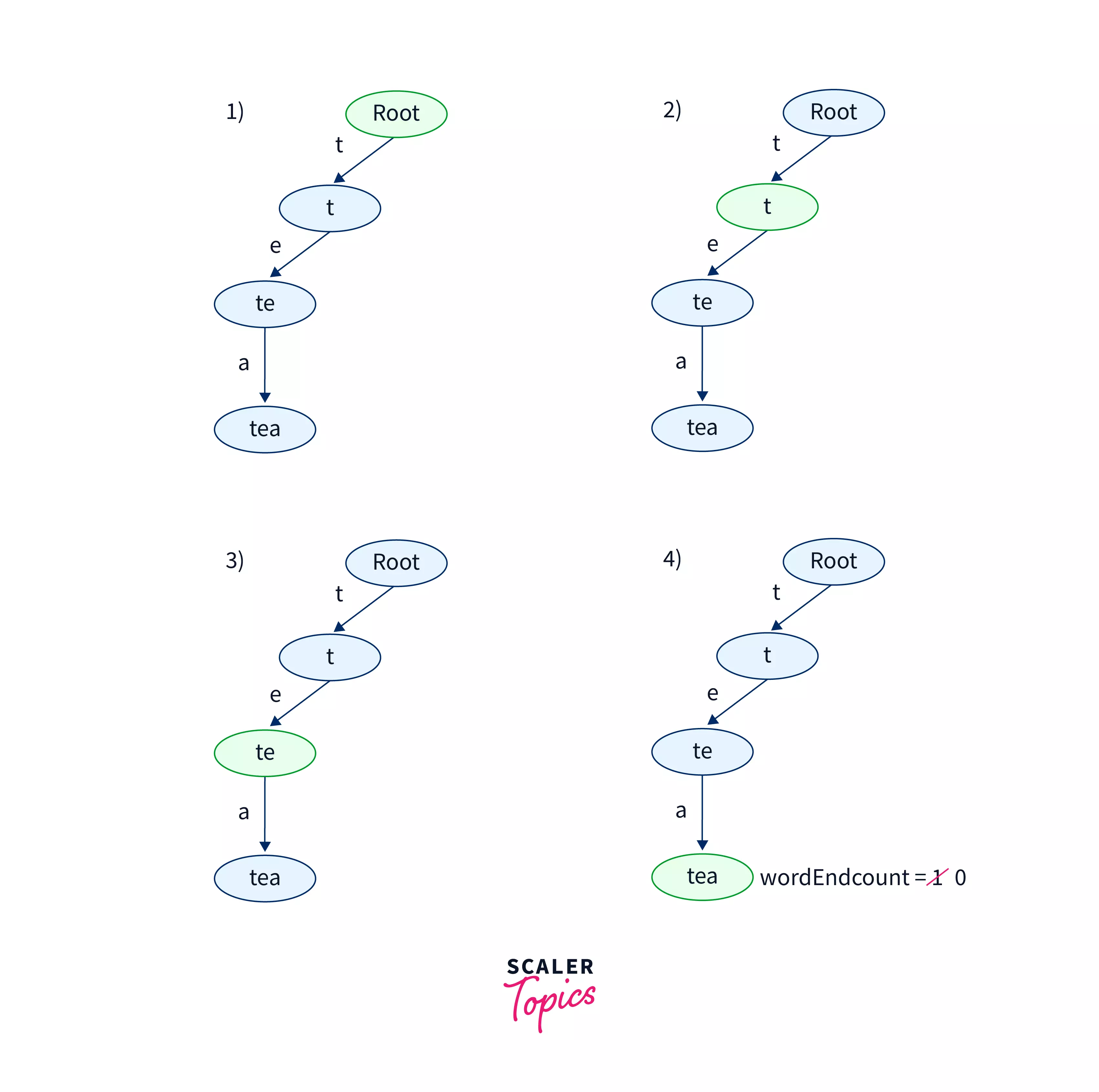
The diagram above shows the steps involved in deleting the string tea from the given Trie.
- At first, we search for the string tea using the same logic discussed in the search operation in a Trie.
- As the string tea is present in the Trie the current node pointer will move from the root node to the last node. The last node represents the string tea. Now we will check if the wordEndCnt for this node is greater than 0 or not. As in this case, the wordEndCnt for the node is greater than 0 we reduce the wordEndCnt for this node and return True.
Note that if we again try to delete the string tea from the Trie after the above operation. We will not be able to delete the string as there was only one tea string the Trie and we already deleted that string. If we try to delete the string then for the last current node we will get the wordEndCnt for the value as 0. So we return a boolean false value.
Implementation of Delete Operation in a Trie Data Structure
Let's define a function delete_key(TrieNode *root,string &queryString) which will take two parameters. The first parameter is the root of the Trie. The second parameter is a string that we want to delete in the Trie. We make a currentNode pointer and initialize it with the root node. Then we loop across the entire length of the string queryString. If there is no such string present in the Trie we return false. Else we decrement the wordEndCnt of the queryString in the Trie and return true.
Applications of a Trie Data Structure
- Autocomplete Feature - Trie data structures are commonly used in implementing the autocomplete features that we see in search engines. If we type a prefix of the desired string then we will see suggestions of many strings that will have the same prefix. This can be efficiently implemented with the help of a Trie as in a Trie the strings having a common prefix share the same ancestors. We can then search at levels below these ancestors and show suggestions based on the popularity of different strings that we come across.
- Spell Checkers - Spell Checkers check whether the typed word is present in the dictionary or not. If the word is not present in the dictionary then it shows suggestions based on the typed word. It may also sort the suggestions based on their popularity. A dictionary can be efficiently implemented using a Trie. Using a Trie makes it easy to search a string in a Trie as well as show suggestions based on a given word.
- String Matching Algorithms - Trie data structures can also be used in string matching algorithms to match a given pattern among a collection of strings.
Advantages of Trie Data Structure
- Tries can implement insert and search operations faster than a binary search tree. Tries are also faster than hash tables as there are no hash functions and collisions in a Trie.
- Tries can be used to order the strings in alphabetical order.
- Tries can be used to implement prefix-based searching which can't be implemented using a Hash Table. This helps in implementing features like autocomplete and spell checks on a given word.
Disadvantage of Trie Data Structure
- The main disadvantage with Trie is that they take a lot of memory for storing strings as compared to other data structures. This is because each node consists of an array of pointers for the child nodes and also contains some additional variables like the wordEndCnt variable we used in the TrieNode structure.
Complete Implementation of a Trie
- At first we make a root node for the Trie with the help of TrieNode() constructor.
- We store the strings that we want to insert in the trie in a vector of strings. Let's name this vector as inputStrings.
- After inserting all the strings in the inputStrings vector with the help of the insertkey() function we search strings with the help of search_key() function discussed above. We store the strings to be searched in a vector named as searchQueryStrings.
- Then we delete the strings present in the deleteQueryStrings vector.
C++ Implementation of Trie Data Structure
C language Implementation of Trie Data Structure
Conclusion
- The time needed for building a Trie data structure is O(N*x). Here N is the number of strings we want to insert in Trie and x is the average length of the strings we want to insert.
- Using a Trie data structure we can insert, search and delete keys in a time complexity of O(k) where k is the length of the key.
- The only disadvantage of using a Trie data structure is that they may end up taking more space than other data structures.
- Trie data structures have many practical applications. Some common examples are auto-completing features, dictionaries, and spell checkers.