Adaptive Methods of Gradient Descent| Deep Learning
Learn via video courses
Overview
Adaptive methods of gradient descent are variations of the standard gradient descent algorithm that adjust the learning rate based on the characteristics of the data and the optimization process. The goal of adaptive methods is to improve the convergence of the optimization by scaling the learning rate in a more suitable way for the task at hand.
Scope
- This article introduces gradient descent and its variants and shows how to use these optimization algorithms in machine learning applications.
- It covers the basics of gradient descent, a widely used optimization algorithm in machine learning.
- We also discuss several variants of gradient descent, including AdaGrad, Adadelta, RMSprop, Adam, and Nadam.
- This also article includes an example of using AdaGrad for gradient descent optimization and a visualization of the optimization process.
Introduction
Gradient descent is a widely used optimization algorithm to find parameter values that minimize a cost function. In machine learning, gradient descent is often used to optimize the parameters of a model to improve its performance. The main idea behind gradient descent is to iteratively improve the values of the parameters by following the negative gradient of the cost function. By taking small steps in the direction that reduces the cost function, gradient descent can efficiently find the optimal values of the parameters. Several variants of gradient descent, including AdaGrad, Adadelta, RMSprop, Adam, and Nadam, use different techniques to adapt the learning rate and improve the convergence of the optimization. This article will discuss these variants of gradient descent and how we can use them in machine-learning applications.
What is Gradient Descent?
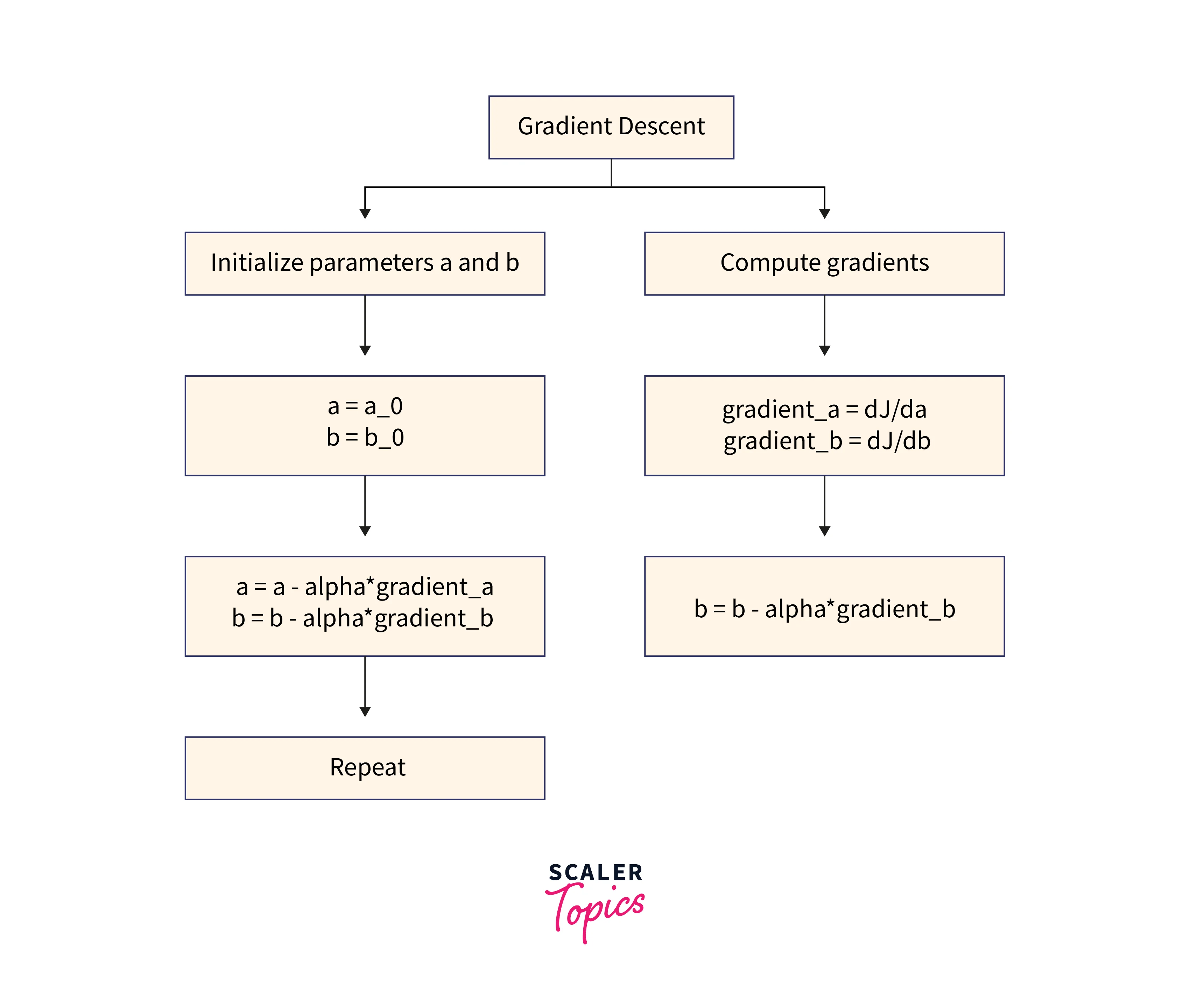
Gradient descent is an optimization algorithm used to minimize some functions by iteratively moving in the direction of the steepest descent as defined by the negative of the gradient. In machine learning, it is commonly used to update the parameters of a model to minimize the error/loss function. Several algorithm variants, such as batch gradient descent, stochastic gradient descent, and mini-batch gradient descent, differ in the number of examples used to compute the gradient at each iteration.
Problem: The Problem is finding the optimal coefficients and for a function that takes inputs and and minimizes the cost function .
Solution: Using Gradient Descent, we start with some initial values for and and iteratively improve these values by following the negative gradient of the cost function .
Steps:
- Compute the gradient of the cost function concerning parameters and
- Update the parameters in the direction that reduces the cost function
- Repeat this process until the cost function is minimized
Note: The learning rate is a hyperparameter that determines the size of the step taken to update the parameters. A larger learning rate can overshoot the optimal values, while a lower learning rate can slow the process.
Adaptive Gradient (AdaGrad)
AdaGrad (Adaptive Gradient) is a variant of the gradient descent algorithm that adapts the learning rate for each parameter individually. The basic idea is that the learning rate will be lower for parameters with a high gradient, and for parameters with a low gradient, the learning rate will be larger. This allows the algorithm to converge more quickly for sparse data.
In the Adagrad algorithm, the learning rate is updated per each iteration as follows :
Here, and are the sums of squared gradients for the parameters a and b respectively. These values are accumulated over time for each parameter. and the parameters a,b are learned via the gradient descent step with the learning rate multiplied by the normalized gradient.
The normalization factor and prevents the learning rate from getting too small, which could slow down the algorithm's convergence and keeps track of the past gradient information.
Gradient Descent With AdaGrad
AdaGrad is particularly useful for handling sparse data and dealing with sparse gradients. Because it keeps a per-parameter learning rate, AdaGrad can handle sparse gradients, allowing each weight to have its learning rate, regardless of the sparsity of the data.
Two-Dimensional Test Problem
The test problem is defined by the function f(x), which takes in a two-dimensional input x and returns the output . This function has a global minimum at x = [0, 0].
Gradient Descent Optimization With AdaGrad
The optimization algorithm starts with some initial values of x, then iteratively improves these values by following the negative gradient of the cost function and finding the optimal values of x using gradient descent involves repeatedly computing the gradient of the cost function with respect to x, and updating x in the direction that reduces the cost function.
In this case, the gradient of the cost function is computed using the grad_f(x) function, which returns the gradient . The learning rate is a hyperparameter that determines the size of the step taken to update x. In this case, the learning rate is set to 0.1.
AdaGrad adapts the learning rate to the parameters, performing larger updates for infrequent and smaller updates for frequent parameters. In AdaGrad, the learning rate is divided by the square root of the sum of the squares of the gradients of the previous steps, which means that the learning rate decreases as the gradient increases.
Output
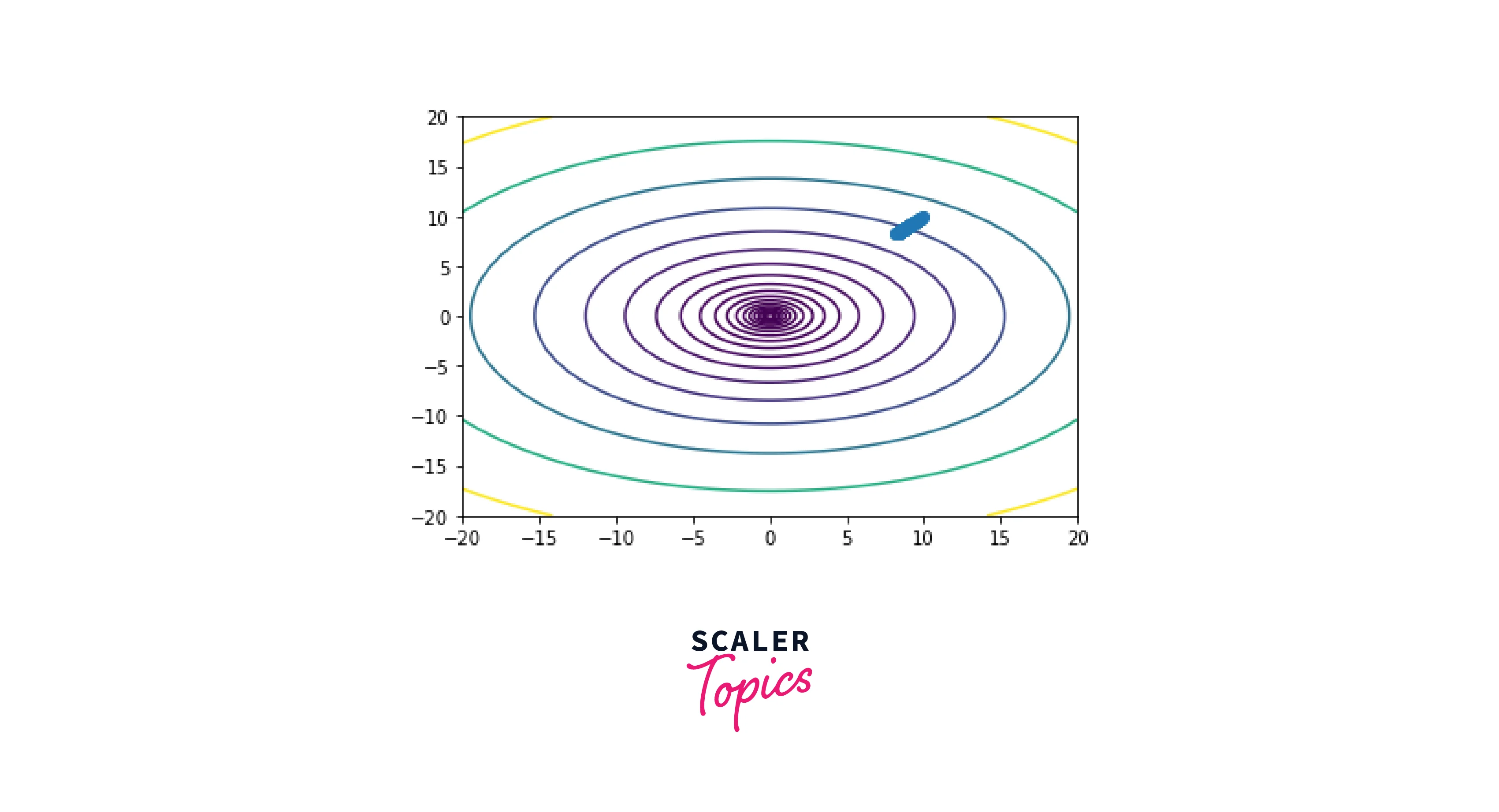
Visualization of AdaGrad
The optimization process is visualized by plotting the cost function and the trajectory of the parameters during the optimization. The cost function is plotted by evaluating the functionf(x) on a grid of points and using the contour function to plot the contours of the cost function.
The trajectory of the parameters is plotted by storing the values of x at each iteration and using the plot function to plot the path of x. Finally, the plot is displayed using the show function.
Output
Adadelta
Adadelta is an extension of Adagrad that reduces the aggressive, monotonically decreasing learning rate of Adagrad by scaling the learning rate based on the moving average of the gradient and the moving average of the squared gradient. Adadelta does not require a manual learning rate and can also handle variable-length sequences.
Formula:
where is a hyperparameter, is the accumulated gradient, is the parameters update, is a small constant that is added to avoid division by zero, and is the gradient at time .
RMSprop
RMSprop is an optimization algorithm that uses the moving average of the squared gradient to scale the learning rate. RMSprop divides the learning rate by the square root of the moving average of the squared gradient, which reduces the learning rate for large gradients and increases the learning rate for small gradients.
Formula:
where decay rate is a hyperparameter, is the accumulated gradient, learning_rate is the global learning rate and is a small constant that is added to avoid division by zero.
Adam
Adam (Adaptive Moment Estimation) is an optimization algorithm that uses the moving averages of the gradient and the squared gradient to scale the learning rate. Adam computes the learning rate for each parameter using the first and second moments of the gradient and adjusts the learning rate based on the exponential decay of these moments. Adam has been shown to work well for many applications and is considered one of the best optimization algorithms.
Formula:
where beta1 and beta2 are two hyperparameters, and are moving averages of the gradients, and is the gradient at time t.
Nadam
Nadam (Nesterov-accelerated Adaptive Moment Estimation) is an extension of Adam that uses the Nesterov momentum technique to accelerate the optimization convergence further. Nadam combines the momentum of Nesterov's method with the adaptive learning rates of Adam and has been shown to perform well on various tasks.
Formula:
Where beta1 and beta2 are two hyperparameters, and are moving averages of the gradients, is the gradient at time t, and learning_rate; epsilon is the same as before.
Conclusion
- Gradient descent and its variants are important tools for improving the performance of machine learning models.
- By iteratively finding the optimal values of the parameters, gradient descent can help machine learning models to make more accurate predictions and generalize better to new data.
- The choice of an optimization algorithm can significantly impact the performance of a machine learning model, and it is important to select the algorithm that is most suitable for the task at hand.
- In summary, gradient descent and its variants are powerful optimization algorithms widely used in machine learning and can be an important tool for improving the performance of machine learning models.