Introduction to groupby in Pandas
Learn via video courses
Overview
Pandas groupby is without a question among the most impressive features that Pandas offers. Groupby is a fundamental concept. We construct a collection of groups and execute a function on them. It's a basic idea, but it's a really useful strategy that's extensively exploited in data analysis. The benefit of groupby stems from its ability to integrate data effectively, both in terms of performance and code.
Introduction
Before we begin, we will assume that you have successfully installed Python on your system and are familiar with the foundations of the Pandas library.
Pandas have grown in popularity among data scientists as a platform for analyzing and altering data. Pandas is a fairly fundamental and flexible language with which we are all acquainted. It provides numerous useful features to assist us in transforming data into the desired format. One of them is groupby, a method that divides DataFrame rows into groups depending on column values. Let's see how we employ it, though.
Pandas dataframe.groupby()
The GroupBy() in Pandas allows you to partition, modify, and merge data sets. This method is frequently used to slice and dice data so that a data analyst could address a specific query. The syntax for the dataframe. groupby() function is as follows:
Syntax DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=NoDefault.no_default, observed=False, dropna=True)
Parameters
It requires the following set of parameters:
| Sr. No | Parameter Name | Parameter Description |
|---|---|---|
| 1 | by | It is employed to find clusters for the groupby() in Pandas. |
| 2 | axis | Its purpose is to specify which axis split should be conducted. '0' indicates that the split should be conducted along the rows, whereas '1' indicates that it should be performed along the columns. |
| 3 | level | Cluster by a certain level or levels if the axis is a MultiIndex (hierarchical structure). |
| 4 | as_index | It is used to choose aggregated output. If the parameter is set to True, an object with group titles as the index is returned. It can only take Boolean values and is set to True by default. |
| 5 | sort | Its purpose is to sort the output. If the parameter is set to True, the output is sorted in descending order. |
| 6 | group | It can only take Boolean values and is set to True by default. It is used to identify pieces by adding group keys to the index. |
| 7 | squeeze | It is used to minimize the number of dimensions. |
| 8 | observed | This only works if one or more of the groupers is Categorical. It can only take Boolean values and is set to False by default. |
| 9 | dropna | It can only take Boolean values and is set to True by default. It is employed to delete all NaN values from group keys that include any. |
Return value
The Groupby() in Pandas produces a groupby object with info about the clusters.
How Does Pandas GroupBy Works?
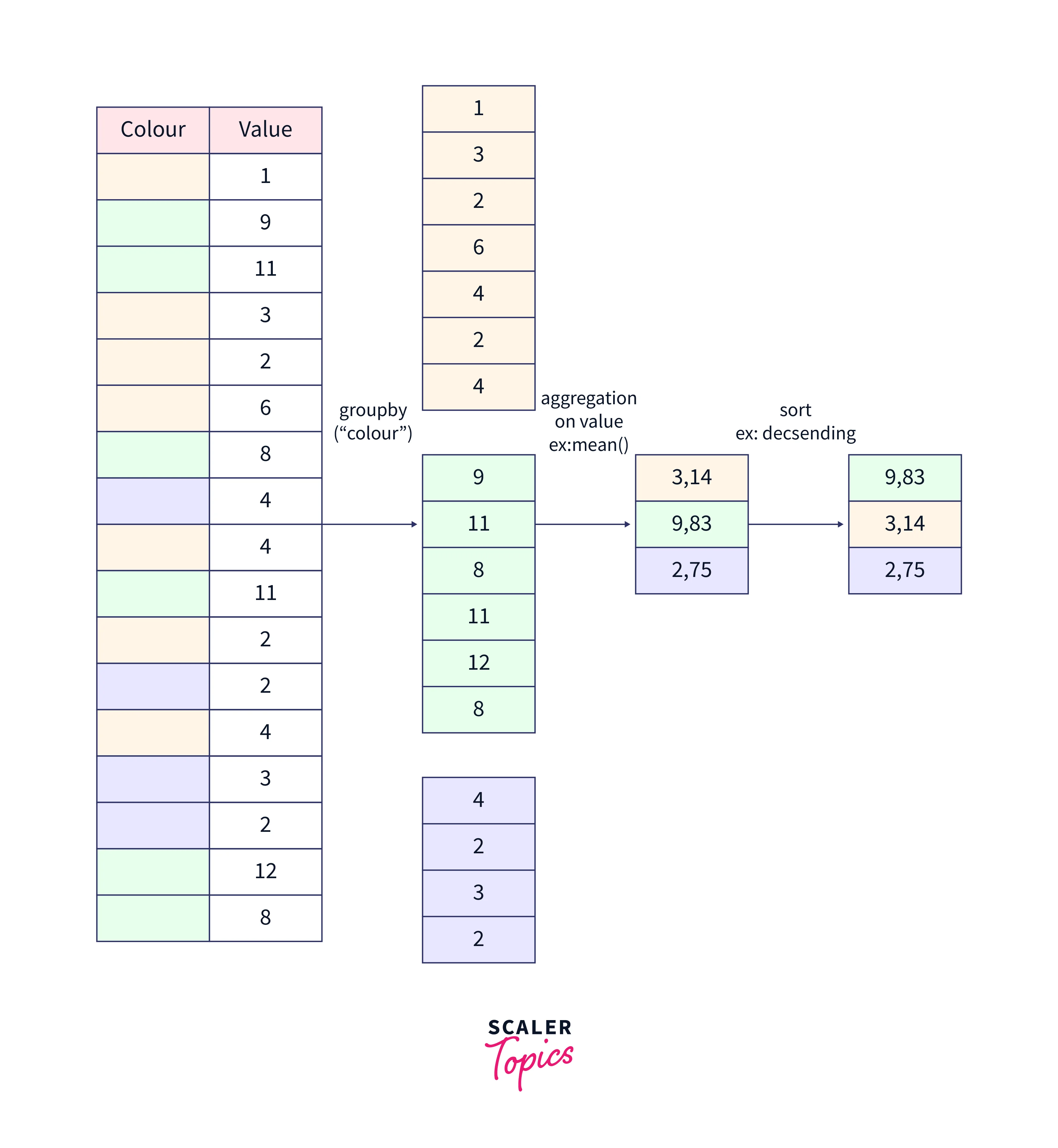
We now have a fundamental understanding of the DataFrame.groupby() methods. Let us now go on to an example that will help us understand it much better.
Example
Before we proceed, let us first create our dataset using Pandas, on which we will run several methods later in the text.
Code:
Output:
Now that we have our dataset, Following these two code lines, the students are clustered and the mean function is applied to the weight column.
Code:
Output:
When you execute the preceding code, the following happens:
First, the unique values from the student column are grouped.
Each group now has its cluster.

Feed the remaining data into the cluster as well.

Finally, execute a method for each cluster's weight column.

This example shows how Pandas' groupby functions work behind the scenes. Let's look at a more concrete example in the upcoming section to understand how the function groupby() in pandas can be employed to retrieve relevant information from data.
How to Split Data into Groups
As we saw in the last part, the basic process of data grouping may be divided into three phases. The first is splitting, which is used to determine the column we wish to 'groupby'. The groupby() in Pandas makes this simple. Second, for each group, execute the method or perform the function. Finally, after executing the function, combine the results into a single object.
Let us first import our dataset before moving on to an example. We'll be employing the customer churn dataset, which can be obtained from here.
Code:
Output:

This dataset contains information about bank clients and their goods.
Use the groupby() Function to Group the Data Based on the “Geography”
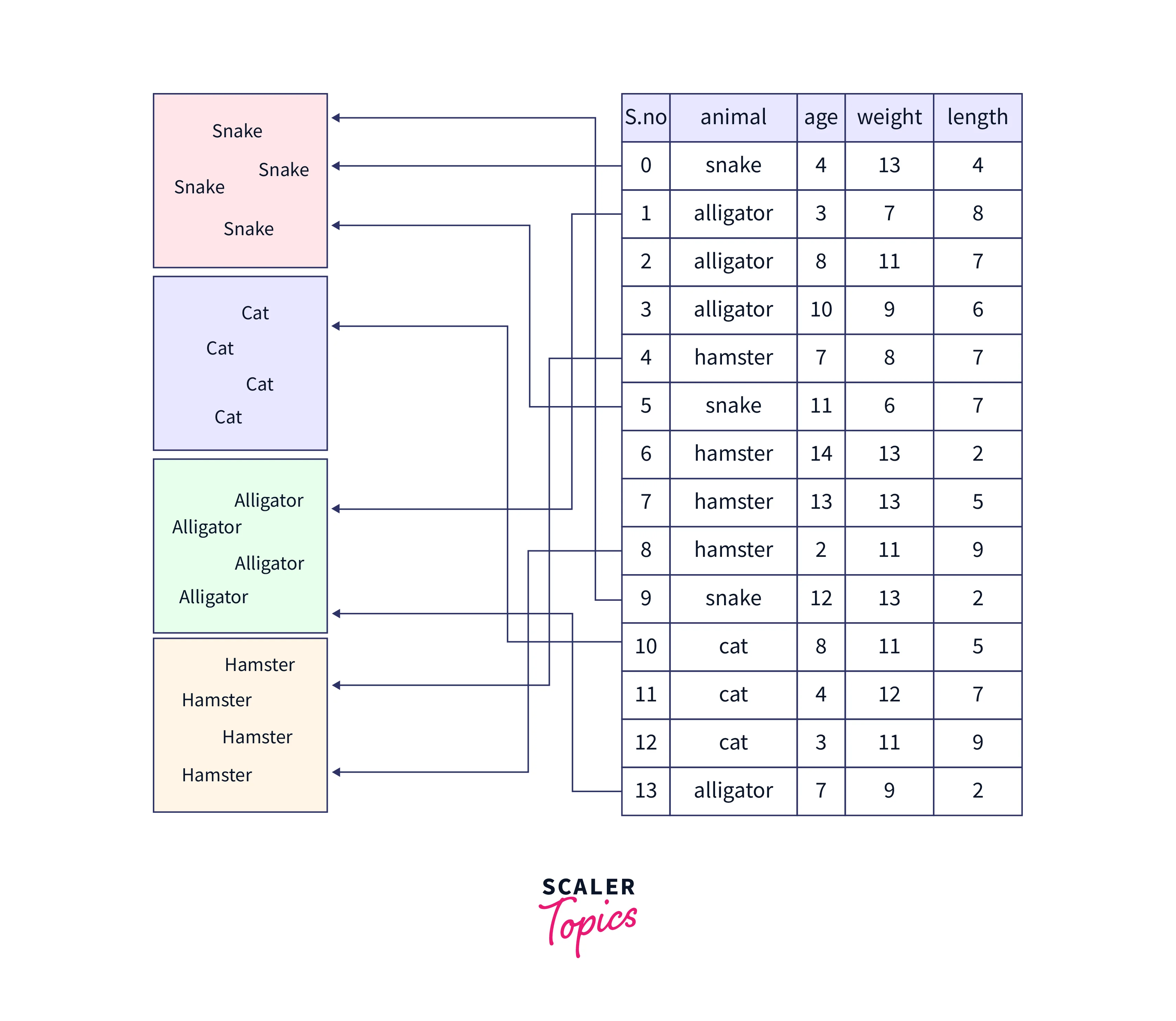
Employing a single key in the Pandas DataFrame, we may build clusters with the groupby() in Pandas. A mapping, method, or the title of a column in a Pandas DataFrame can serve as the key. The groupby key in our example is a column called "Geography."
Code:
Several approaches may be used to examine the various elements of the output groupings. The groups method may be employed to display the index labels of rows with similar cluster key values. The result will be a dictionary, with the keys being the cluster keys and the values being row index labels that share the identical cluster key value.
Code:
Output:
Row indices '[0, 2, 3, 6, 8...] have the group key value 'France,' as seen in the preceding code, and hence have been clustered together. The row indices [7, 15, 16, 26, 28, 32...] and [1, 4, 5, 11, 14, 17, 18...] have been combined since they share the same value, which is "Germany" or "Spain," respectively.
Use the groupby() Function to Form Groups Based on More Than One Category
We may also use numerous keys to make groups in Pandas by giving the array of keys to the argument of the groupby method.
Code:
Using the groups approach, you can see the groupings.
Code:
Output:
View Groups with Pandas GroupBy
There are several methods to visualize the groups formed by the groupby() in pandas. As you may have seen, we utilized the group's property in the previous section to inspect the groups formed by the groupby method.
Code:
Output:
In addition to the approach described above, we may employ the following code to retrieve the names of the groups.
Code:
Output:
Iterating Through Groups with GroupBy
Assume we want to extract the name and data for each group generated using the function groupby in pandas independently. We can employ the following code:
Code:
Output:
get_group() Method in Pandas
Until now, we've seen many methods for extracting all of the group names produced by the function groupby in Pandas. When we just need one group, we may obtain the data of that group by supplying the group key value of a specific cluster to the get_group method.
Code:
Output:
Applying Functions on a Group
Several methods may be applied to groups to provide a statistical summary, alter the data of the clusters, or scan the clusters based on a set of criteria.
We may divide the methods into three major categories:
- Aggregation: Aggregation methods are employed to calculate various statistical values of the groups, which can be beneficial for inferring trends or patterns of data existing in the groups.
- Transformation: Transformation methods are employed to make modifications and tweaks to the group's data.
- Filtration: Filtration methods are employed to subset groupings based on specific criteria.
Now we'll go through each method in detail.
Aggregation with GroupBy Function
We may use aggregation functions on clusters such as 'sum' to obtain the summation of a group's numeric features, 'count' to compute the number of instances of each group, 'mean' to calculate the arithmetic average of a group's numerical features, or 'std' to retrieve the standard deviation of a group's numeric characteristics. To execute the aggregation functions, we utilize the aggregate method.
Code:
Output:
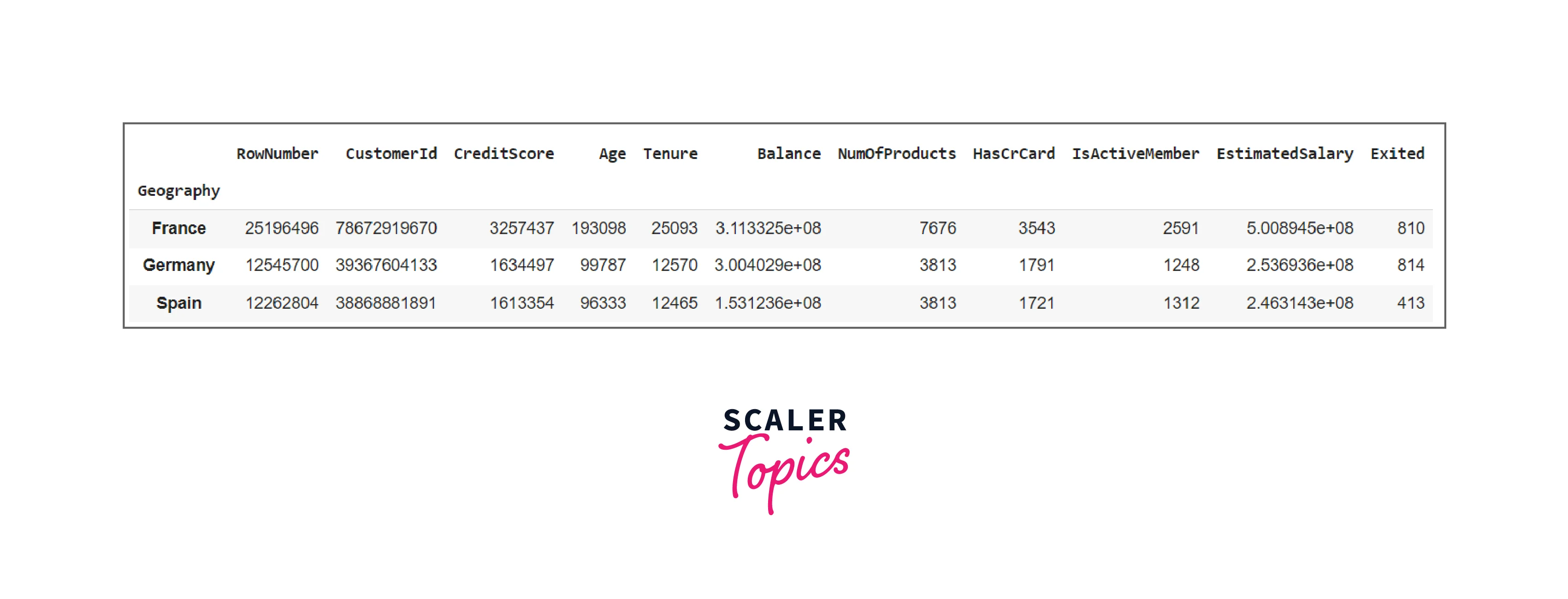
You may display several statistical data of a group at a glimpse by providing an array of methods to the aggregate method.
Code:
Output:
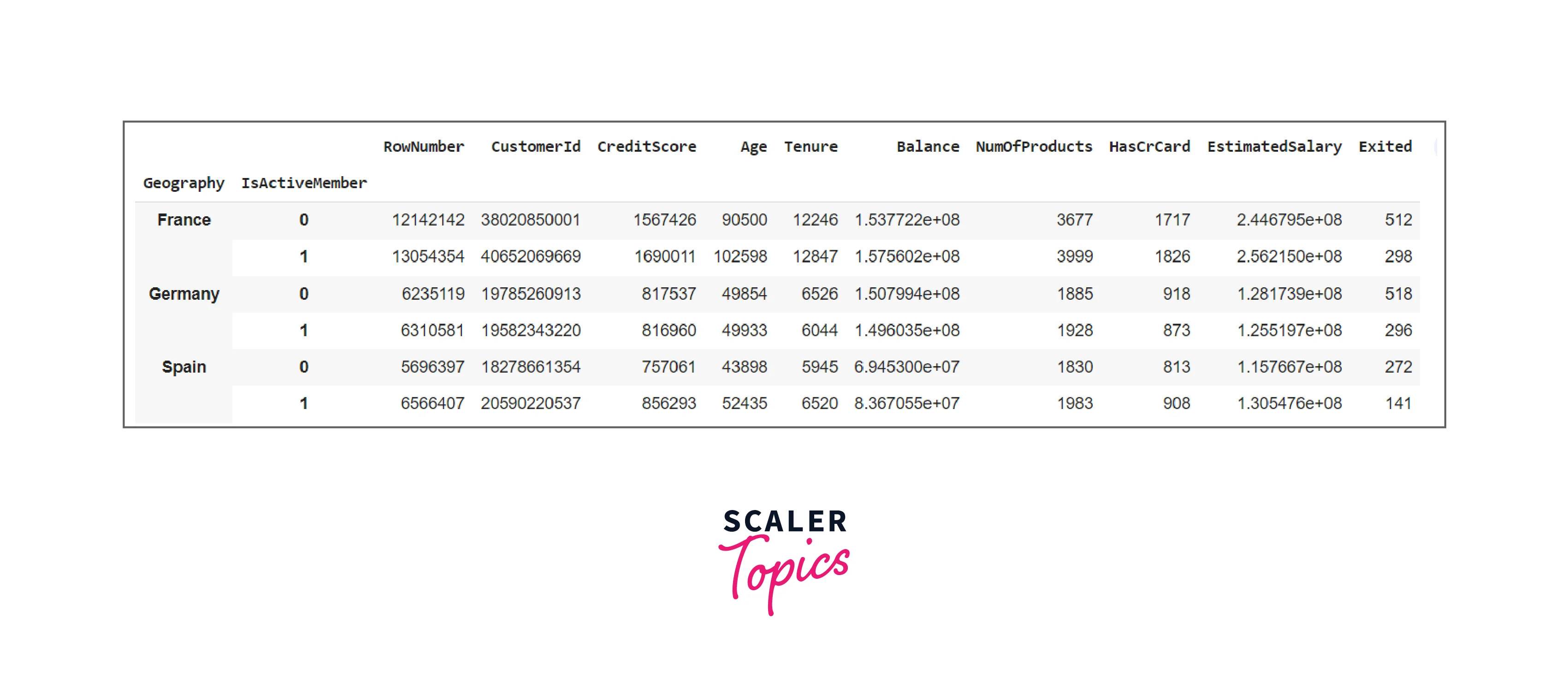
It isn't required to use the same grouping method on all keys. A dictionary can also be used to apply distinct methods to different group keys. The dictionary's keys will be group keys, and the values of the keys will represent the method that will be executed for them.
Code:
Output:
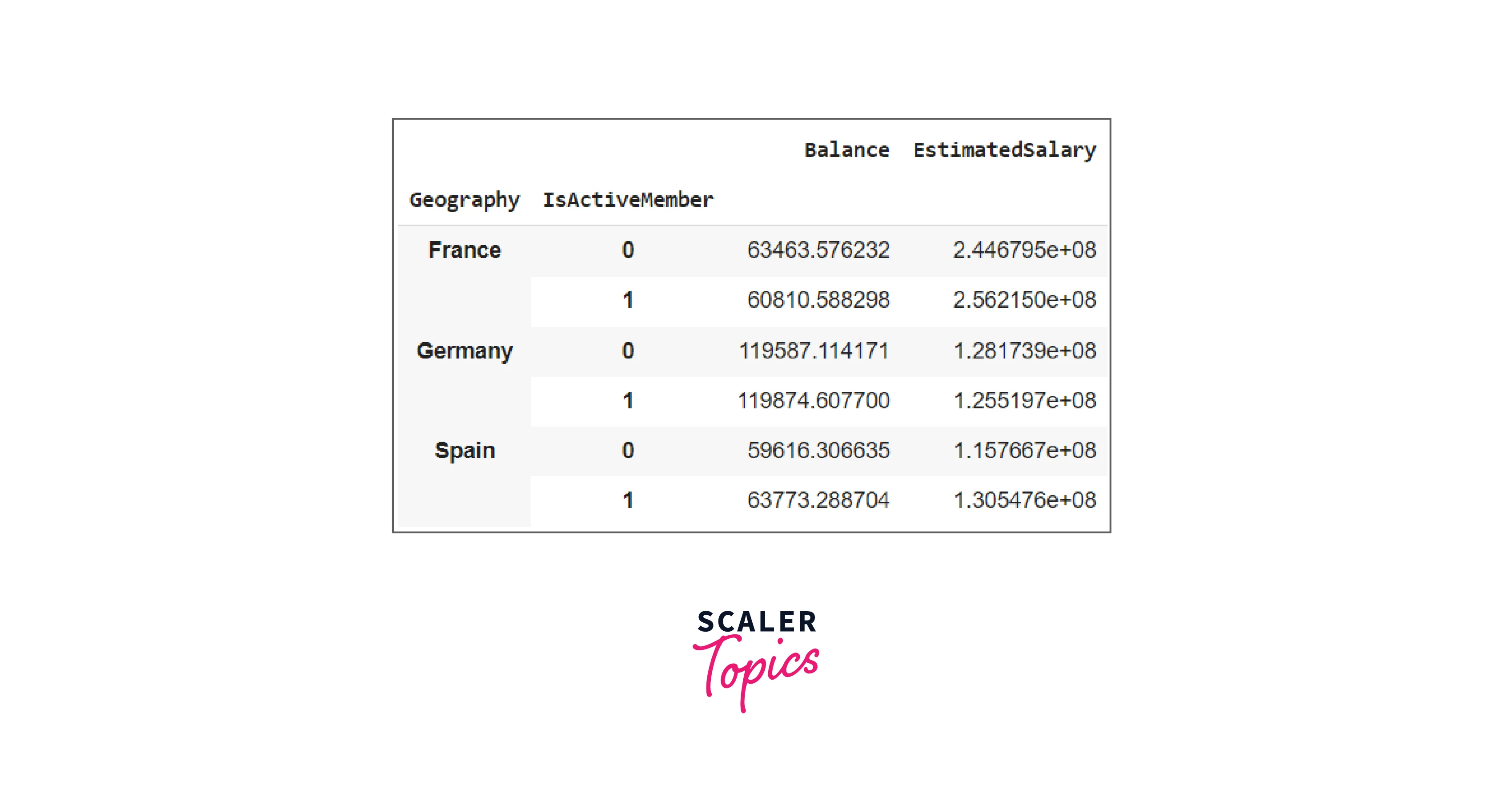
Transformation with GroupBy Function
The transformation methods are employed to modify each group's data. They may be employed to perform crucial strategies like standardization for scaling the group's data. It produces an output that is similar in size to the group segment. Otherwise, we broadcast the output to the group segment's size. It works on a column-by-column basis. This cannot be used for in-place procedures. The generated groups must be regarded as immutable, and applying transformation methods to them might provide undesired outcomes. Consider the following example
Code:
Output:
Filtration with GroupBy Function
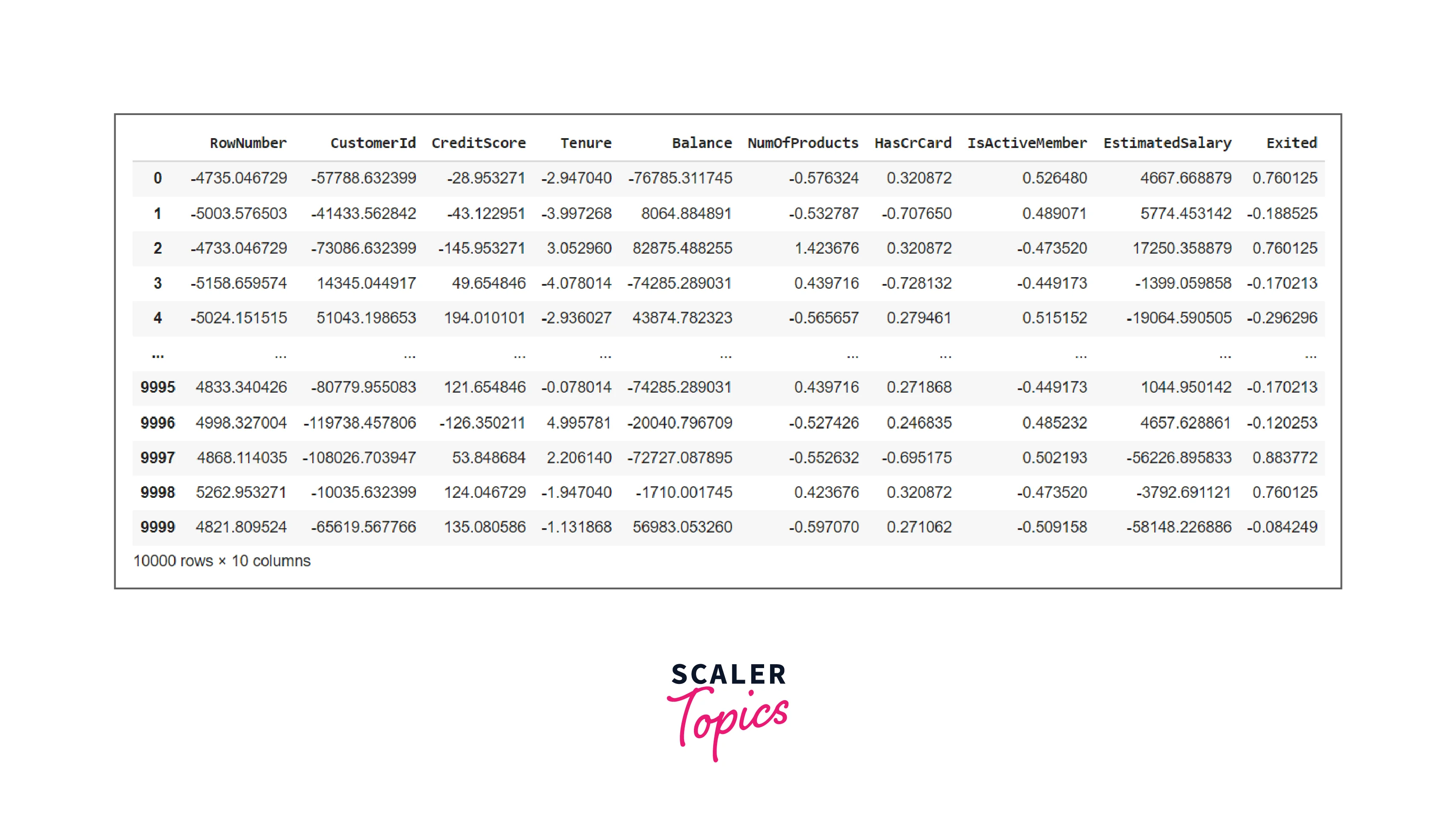
We can filter out data that do not meet specific criteria. To perform the filtration functions, we employ the filter method.
Code:
Output:

The results generated from the previous code only included the segment of the group where our "Balance" column included a mean balance greater than 10K.
Pandas GroupBy vs SQL
As most likely Pandas users are acquainted with SQL, this section will offer some instances of how SQL GroupBy functions might be accomplished using the method groupby() in Pandas.
The groupby() function in pandas is used to accomplish SQL's GROUP BY functions. Getting the number of entries in each cluster across a dataset is a typical SQL procedure. For example, a query that returns the count of customers from a certain geographic region is:
Code:
Output:
The pandas counterpart, as you may recollect from the text, would be:
Code:
Output:
Did you observe anything? We employed size() rather than count() in the preceding Pandas code. This is because count() executes the method to each column, reporting the count of NaN entries contained within each.
Code:
Output:

However, if we wanted to employ the count() method, we might have implemented it in a single column.
Code:
Output:
As you may recollect from the article, many methods can be used at the same time. For example, if we desire to observe how the average of a customer's anticipated wage varies by geographic area, we may employ agg(), which allows us to supply a dictionary to your aggregated DataFrame that specifies which methods to apply to certain columns.
Code:
Output:

SQL counterpart would be:
Code:
Output:
This concludes our article, kudos! You now have a firm knowledge of Pandas’ groupby() method and can use it to extract relevant information from numerous real-world instances.
Conclusion
This article taught us:
- The dataframe. groupby() method in Pandas is used to divide data into groups depending on the specified criteria.
- Panda objects can be divided along any axis.
- The abstract concept of grouping is to offer a label-to-group name mapping.
- The groupby() in Pandas is a method that enables us to execute a function or transformation to all groups and aggregate the results into an output.
- When we pass various group keys, only rows whose group key values align with all of the group keys are added to a group.
- The groupby() function in pandas is used to accomplish SQL's GROUP BY functions.