Handling Large Datasets in Pandas (Memory Optimisation)
Learn via video courses
Overview
Pandas is a great tool to handle small datasets around size 2-3 GB. To handle the large datasets in pandas there are several techniques like sampling, chunking, and optimization are used to handle large datasets in pandas.
Scope
In this article, we will go to learn:
- What is the problem with the large datasets?
- How to handle large datasets using different methods like sampling and chunking.
- How datatype optimization of Integers, Float, Datetime, Categorial, and typecasting can help to work with large datasets.
- We will also discuss some alternatives for pandas like Dask, Ray, Modin, and Varex.
Introduction
Pandas can perform very well while working with small datasets, but it's not recommended to use pandas in large datasets due to preprocessing and memory usage. In Big Data, pandas is used in various ways. There are different methods like Sampling, which creates random samples from the data, and chunking, by which data can be split into chunks. By optimizing the data types of the data objects, memory usage can be improved.
The Problem with Large Datasets
When the dataset is small, around 2-3 GB, Panda is a fantastic tool. However, using Pandas is not recommended when the dataset size exceeds 2-3 GB. Before performing any processing on the DataFrame, Pandas loads all of the data into memory. Therefore, you will encounter memory errors if the size of the dataset exceeds the RAM. As a result, datasets larger than what can fit in RAM cannot be handled by Pandas.
Sometimes, even when the dataset is smaller than the available RAM, we still experience memory problems. Because of the creation of a copy of the DataFrame during preprocessing and transformation by Pandas, the memory footprint is increased, leading to memory problems.
However, it is possible to use Pandas on datasets that are larger than what can fit in memory. With some techniques, Pandas may be used to manage big datasets in Python. But only to a certain point.
Let's look at some methods for using Pandas to manage bigger datasets in Python. You can use Python to process millions of records using these methods.
Methods to Handle Large Datasets
There are various methods for handling large data, such as Sampling, Chunking, and optimization data types. Let's discuss this on-by-one.
Let's first load the dataset from GitHub link and analyze it.
Code#1:
Output:
Explanation: In the above code example, Pandas is imported as pd, and CSV data is loaded from the GitHub link using the .read_csv() function. By using the.head() method, we get the starting rows of the data, by default first five rows.
Sampling
For randomly selecting N items from a list, use the .sample() method. The sample() function in the random module of Python allows for random sampling, which selects many elements at random from a list without repeating any of the elements. It gives a list of distinct items selected at random from the list, sequence, or collection. It is referred to as random sampling without replacement.
Code#2:
Output:
Explanation: In the above code, the random module is imported, and then by using the .sample() function of the random module, we get the random data of the specified sample. In this case, 200 random samples from the data are generated.
Chunking
If you are working with large data, we can split the data into several chunks and then can perform operation data cleaning and feature engineering on each chunk. Additionally, you have two choices based on the kind of model you want to use:
- If the model of your choice allows for partial fitting, you can incrementally train a model on the data of each chunk.
- For each chunk, train a model separately. Predict with each model and then pick the average or majority vote as the final prediction to determine the score for unseen data.
Let's look at below examples:
Code#3:
Output:
Explanation: By passing the chunksize argument, we are constructing a chunk with a size of 1000 in this case. It returns the TextFileReader object for iteration as output.
Code#4:
Output:
Explanation: In the above code example, for loop is used to iterate each chunk, and the .shape method is used to get the shape of each chunk.
Optimizing Data Types
We can optimize the data types to reduce memory usage. By using the memory_usage() function, we can find the memory used by the data objects. It returns a series with an index of the original column names and values representing the amount of memory used by each column in bytes.
The syntax of memory_usgae() as follows:
Parameters:
- index: Specifies whether the returned Series should include the memory usage of the DataFrame's index. If index=True, the output's first item's memory usage is given.
- deep: If True, thoroughly analyze the data by asking object types how much system-level memory they use, and include that information in the returned results.
1. Integers
Code:
Output:
Explanation: In this code, columnsTMax of the int64 datatype is converted into the int32 datatype using the .astype() method. We can see the difference between the memory used by the TMax column. There is a decrease in memory usage.
Code:
Output:
Explanation: Here, the datatypes of the TMIN and TMAX column is changed from int64 to int8 using the .astype() function.
2. Float We can optimize the float data from float64 to float16 by using the .astyype() function. This will help reduce the memory used by large data and makes it easy to handle large data.
Code:
Output:
Explanation: In this code example, the datatype of the AWND column is changed from float64 to float16 by using the .astype() function. Here, .dtypes is used to find the datatype, and .memory_usage() is used to find the memory usage. There is a huge difference between memory usage. It decreases from 39560 to 9986 i.e, approximately a 25% reduction.
Code:
Output:
Explanation: Here, we change the data type of the AWND and PCP columns from float64 to float16 using the .astype() function. The .dtype method is used for finding the datatype, and .memory_usage is for finding the memory occupied.
3. DateTime Datetime-type data can be optimized by using the to_datime function of pandas. This function is used to convert the scalar, array-like, Series, or DataFrame /dict-like into the DateTime object of pandas.
Code:
Explanation: In the above code, we get the two rows from the start of the data by using the .head() function.
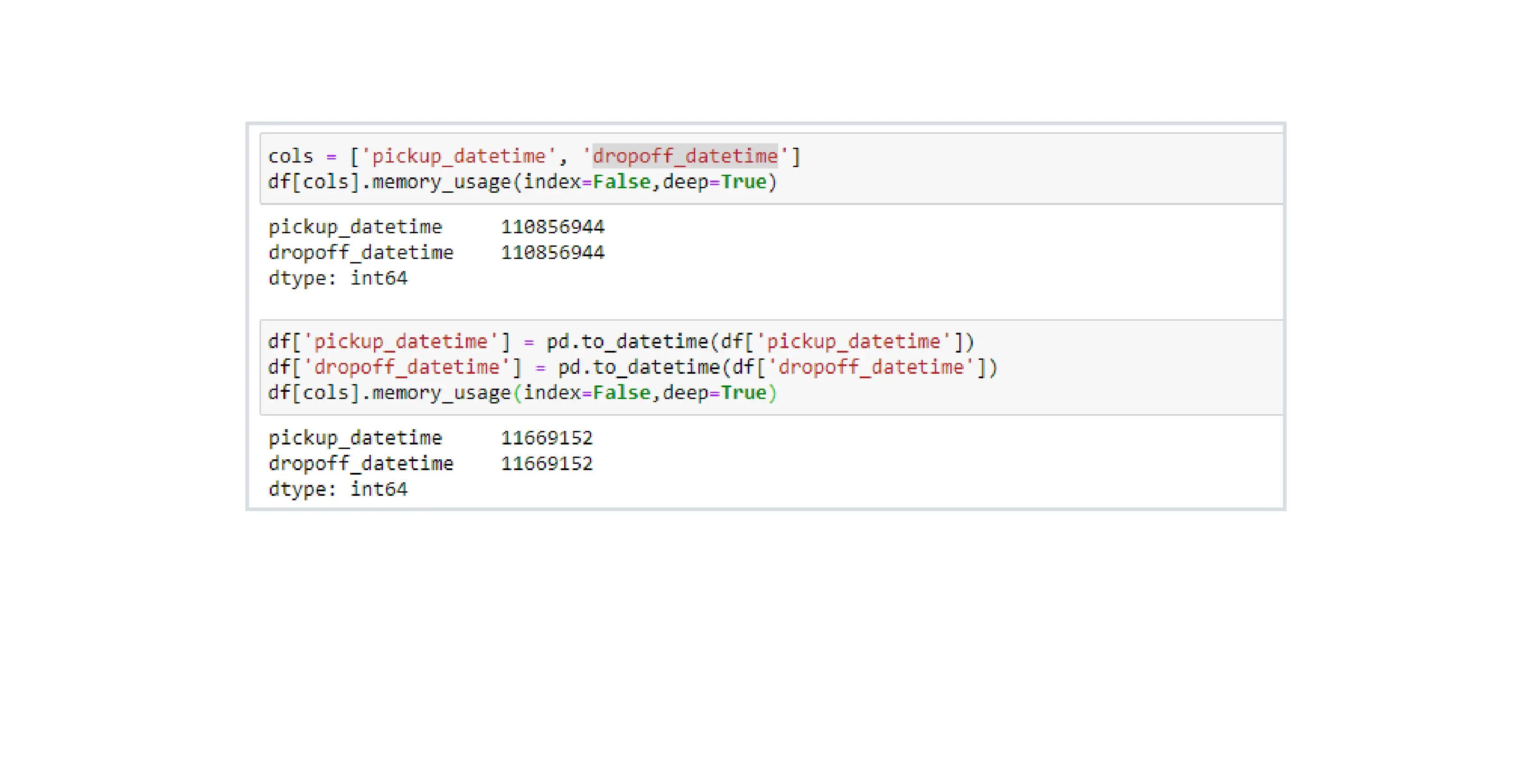
Explanation: Here, In the above code, the columns pickup_datetime and dropoff_datetime are of object datatype by default. The data type of these columns can be converted to DateTime format using the .to_dateime function.
4. Categorical The non-numeric columns of DataFrame are assigned as object data types which can be changed to category data types. Usually, the non-numerical feature column has categorical variables which are mostly repeating. For example, the gender feature column has just two categories, ‘Male’ and ‘Female’, that are repeated over and over again for all the instances which are re-occupying the space. Assigning it to a category datatype is a comparatively compact representation.
Code:
Output:
Explanation: In this code example, The NAME column of the string datatype is converted into a category datatype by using the .astype() function. Here, .dtype is used for finding the datatype, and .memory_usage() is used for finding the occupied memory.
5. TypeCasting The .read_csv function of pandas has a type parameter that takes user-provided data types in a key-value format that can be used in place of the standard ones. The parse_dates parameter can take a Date feature column as an argument.
Code:
Output:
Explanation: In this code example, the data type of each column is downgraded and stored in the dict_dtype dictionary. For the Date feature, parse_dates is used. After optimizing all the column datatype, there is a huge decrease in the memory usage, i.e, from 1.3 MB to 447.9 KB.
Pandas Alternatives to Handle Large Datasets in Python
Several libraries are available that handle out-of-memory datasets more effectively than Pandas since the Pandas DataFrame API has become so well-known.
Dask
Python has a library called Dask that allows for parallel processing. In Dask, there are two main sections: Dask is a Python package for parallel computing in Python. There are two main parts to Dask, there are:
- Task Planning: It is used, like Airflow, to optimize the computation process by automatically carrying out activities.
- Big Data Gathering: Parallel data frames, such as Numpy arrays or Pandas data frame objects, are designed specifically for parallel processing.
Ray
For scaling Python and AI applications, there is a framework called Ray. Ray is a collection of libraries for streamlining ML computation that includes a core distributed runtime called Ray AIR. Researchers at Berkeley created Ray with current Pandas users in mind. Multiprocessing is another technique Ray uses, and it also aids in handling data that is larger than memory.
Modin
Your panda's notebooks, scripts, and libraries may easily be made faster with Modin, which leverages Ray or Dask. In contrast to other distributed DataFrame libraries, Modin offers full compatibility and integration with current pandas programs. The results are the same even when using the DataFrame function Object(). You can continue using your old panda's notebooks, untouched, while getting a significant speedup owing to Modin, even on a single system, because Modin acts as a drop-in replacement for pandas. You may use Modin exactly like pandas after making the necessary changes to your import declaration.
Vaex
Vaex is a Python library providing Pandas-like interfaces for processing and examining large tabular datasets. According to Vaex documentation, it can compute statistics like mean, total, count, standard deviation, etc. on an N-dimensional grid at a rate of up to a billion (109) objects/rows per second. Vaex is hence a substitute for Pandas that are likewise used to speed up execution. Because of the similarities between the Vaex workflow and the Pandas API, using Vaex won't be difficult for anyone already familiar with Pandas.
Conclusion
- For large datasets that exceed 2-3 GB, using pandas is not recommended because it gives some memory errors. But by using some techniques, pandas can be used in big data.
- There are various methods to handle large data, such as Sampling, Chunking, and optimizing the datatypes.
- In Sample, we can get some random samples from the data which helps us to analyze the data like what it contains, etc.
- Chunking is a process in which large data can be split into chunks and then used for processing.
- We can optimize the datatypes like integers datatype of int64 can be transformed into int8, float datatype of float64 can be changed into float16 etc.
- Data optimizations help to reduce the size of the data.
- There are several pandas alternatives to handle large data. Some of them are Dask, Ray, Modin, and Vaex.