Read and Write Data from Database in Pandas
Learn via video course

Overview
Pandas provide essential data structures like Dataframes and Series to store and operate on structured tabular data, which makes performing operations on them much more feasible than directly mutating data from sources such as CSV, text, or Databases. With Pandas, a database can be directly accessed using SQL query and stored and operated using a dataframe.
Scope
- This article discusses methods to perform various operations on data from database tables with pandas dataframes.
- The article explains methods to read from databases into pandas dataframes, consequently performing operations on dataframes.
- We discuss methods that allow manipulation and summarising data with dataframe objects such as mean and describe.
- Finally, we discuss the to_sql that allows writing data to databases from dataframes.
Introduction
Pandas library comes with functions that simplify reading and writing data to and from a database. These methods allow for performing complex operations and analysis, which may be too complicated for SQL queries as well as allowing for visualizations and creating summaries from data. Pandas utilize SQLAlchemy under the hood for database operations and provide simpler abstractions. There is a fallback provided for SQLite a native python module(although it doesn't support all methods). To work with SQL Databases, initially, a database engine is initialized with the database URI, and a connection is created. This engine allows for executing queries and fetching results, which are then converted to a dataframe object.
Reading the Data Using read_sql_table() Method
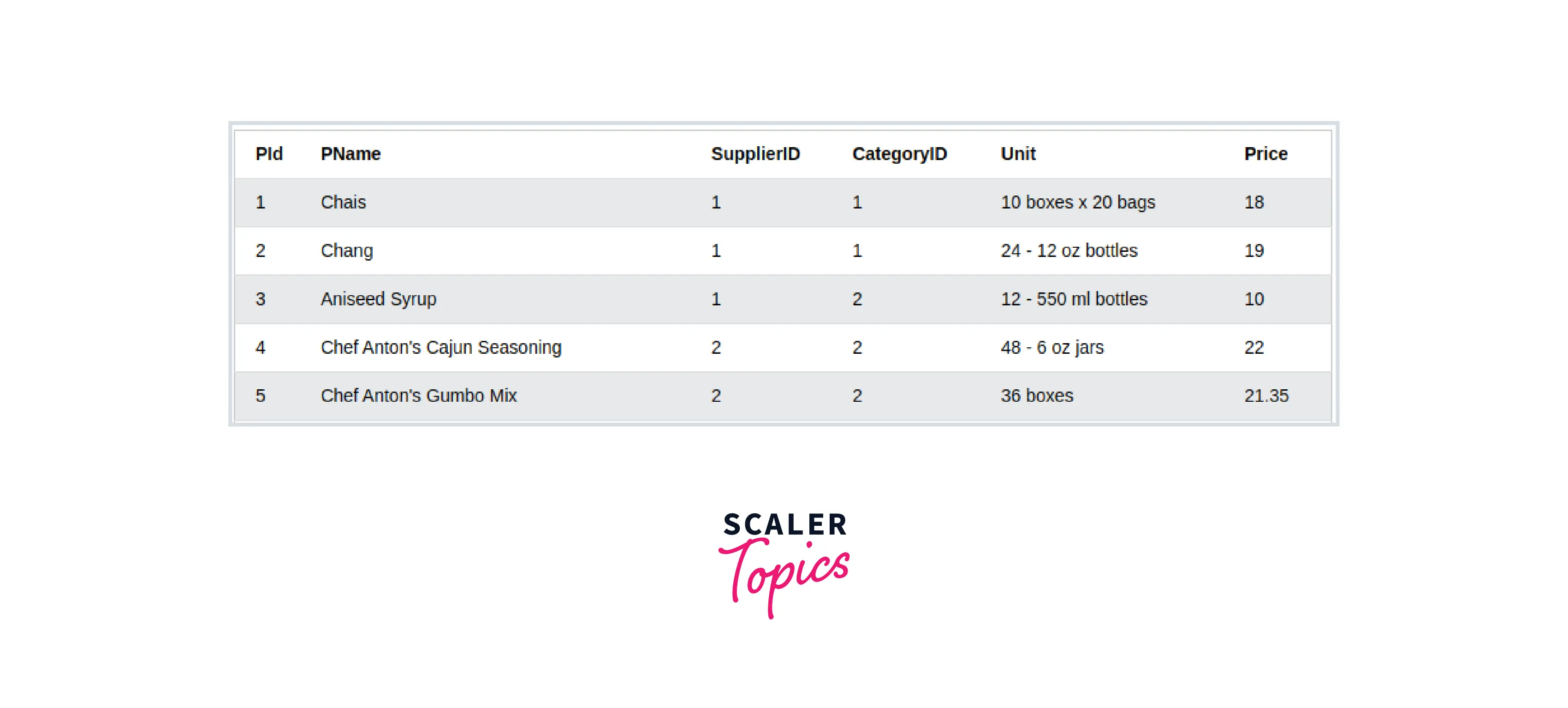
To read a complete database table into pandas dataframe, we can use the read_sql_table() method, which accepts a Table Name and an SQLAlchemy connectable (Database URI as string). It returns a dataframe with data from SQL database table.
Note: For using read_sql_table(), you need to have the optional SQLAlchemy dependencies installed_
What is the create_engine() Method?
The create engine() method creates an engine object from a database URI so that SQLAlchemy may connect to it. For each database you are connecting to, you only need to construct the engine once.
Different Operations
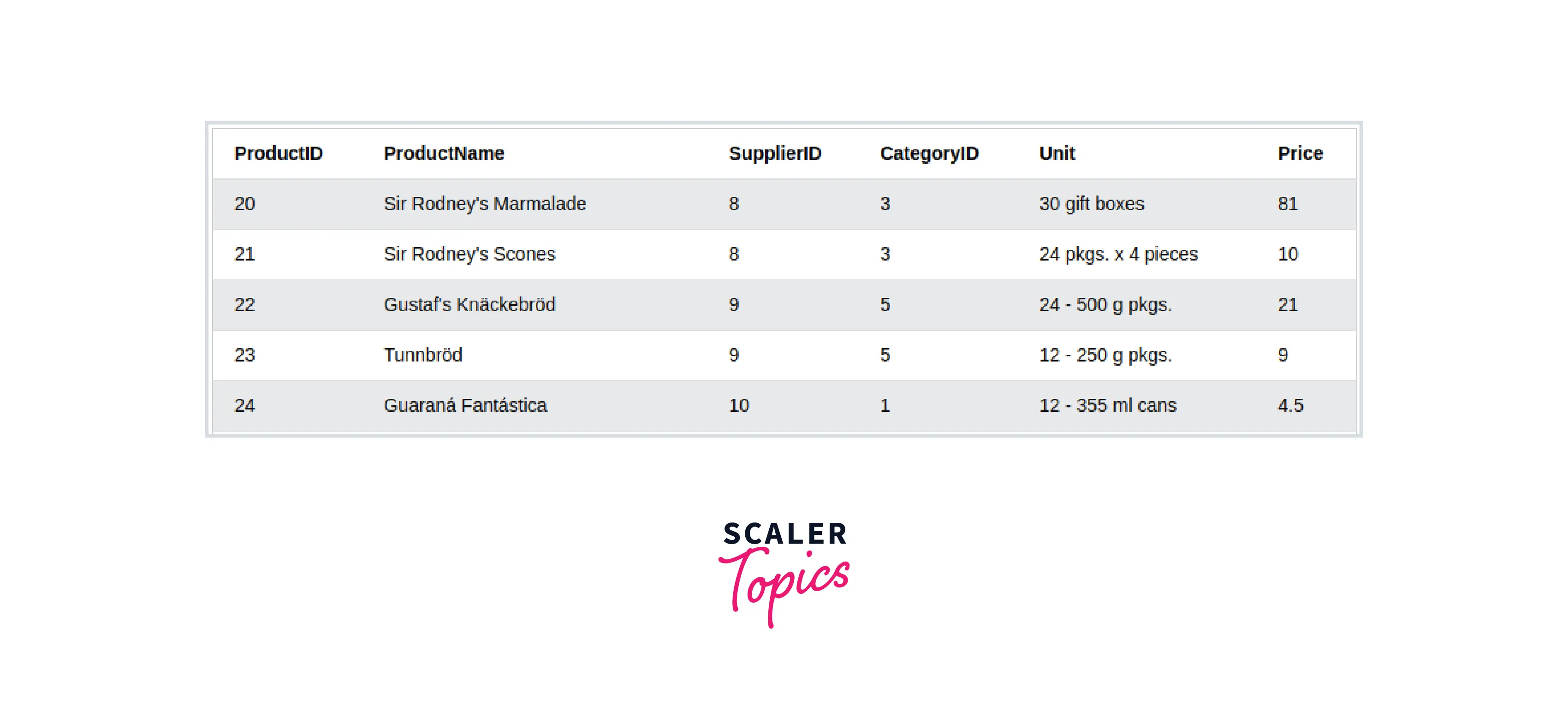
- Slicing of Rows Once we read the data from Database, using pandas' read_sql_query, we can slice selected rows into a dataframe, this allows performing all the operations on a selected range of data items.
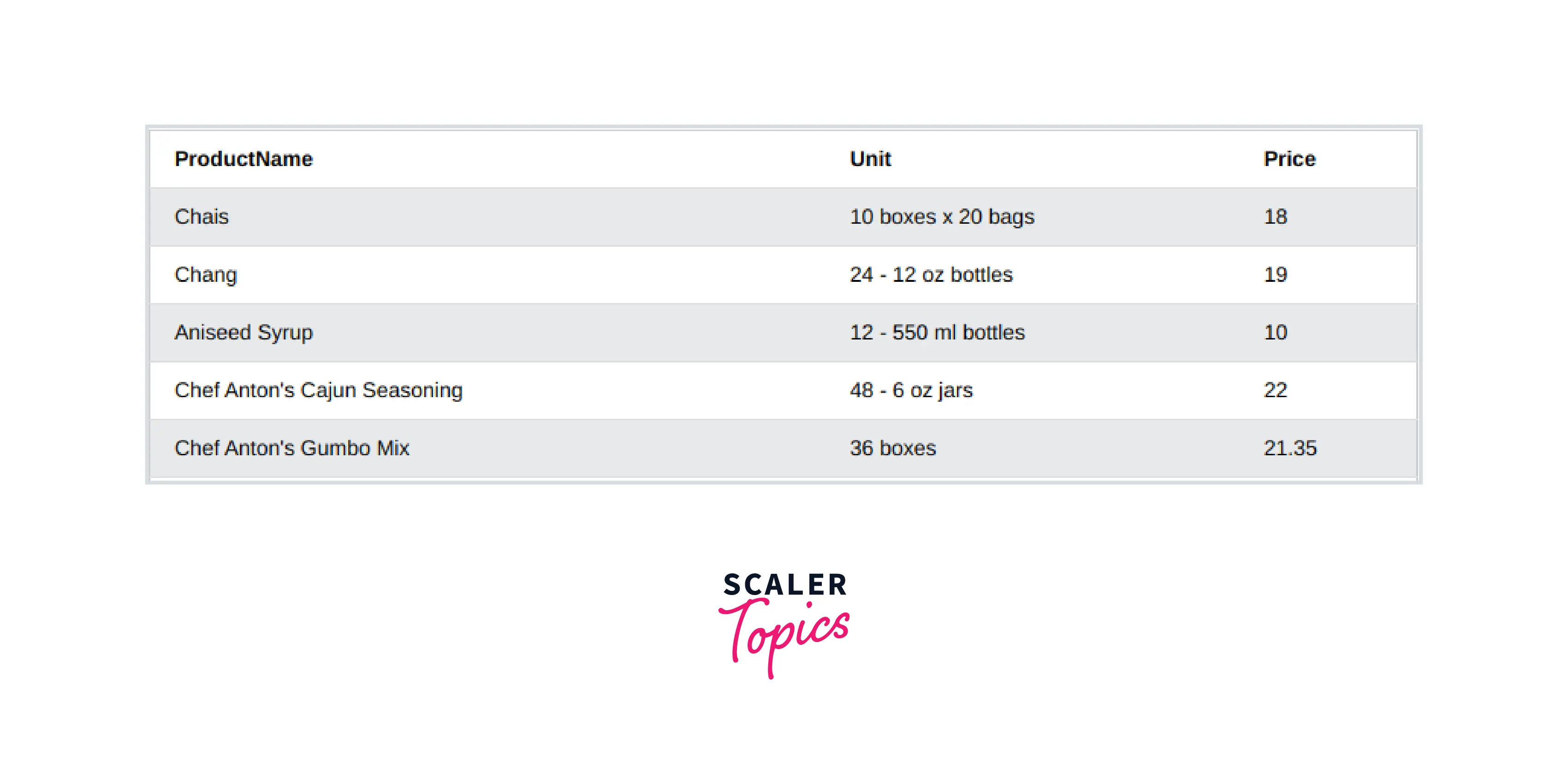
- Selecting Specific Columns We can also select a specific column or a subset of columns from the dataset using .loc on the primary dataframe to which the data is loaded from the database. This works similarly to projections in a database.
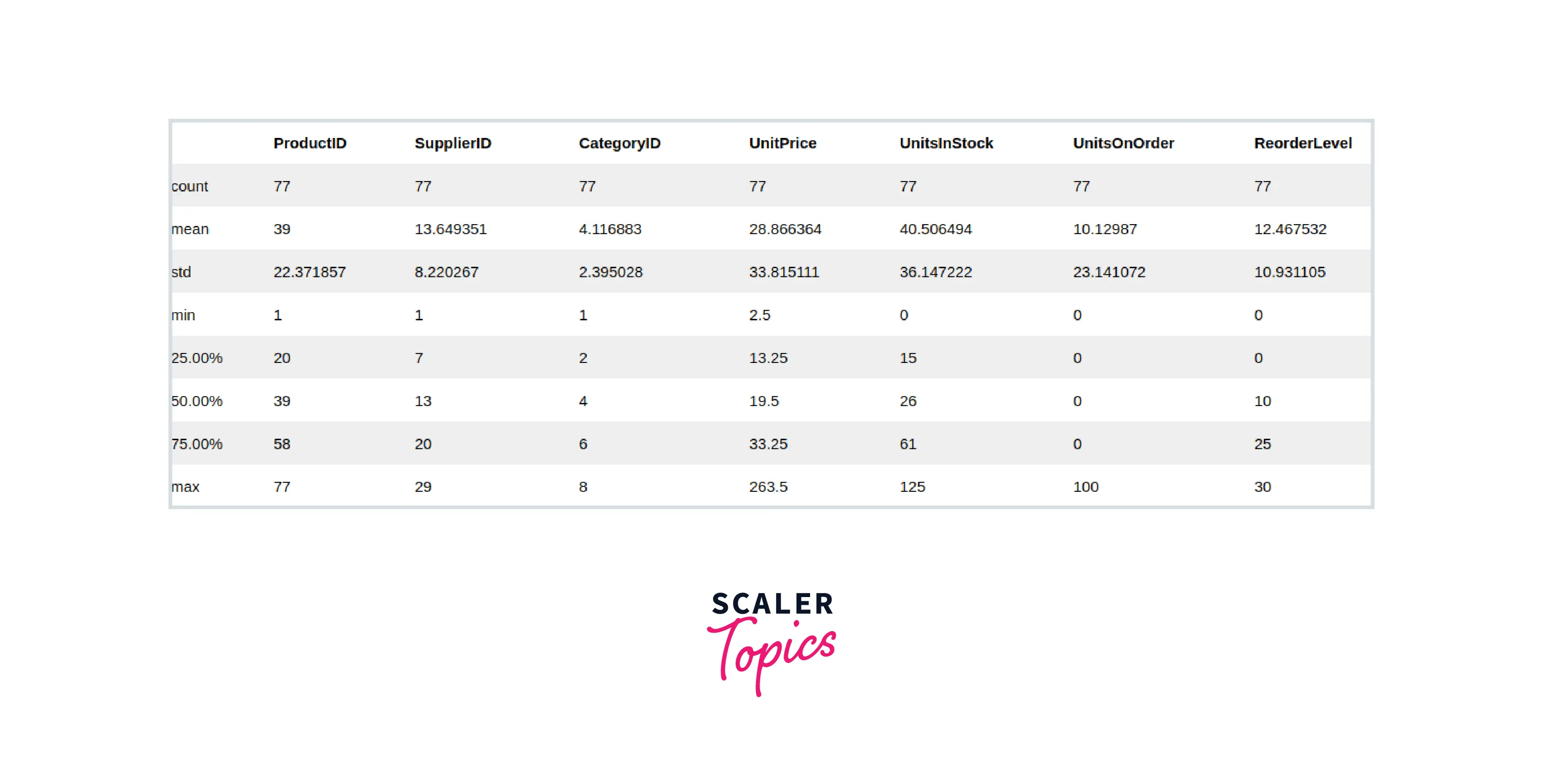
- Summarize the Data With the data loaded from the database table into a pandas dataframe, we can get the statistical summary of this data using the .describe method of the pandas dataframe object. This provides primitive insights into the data.
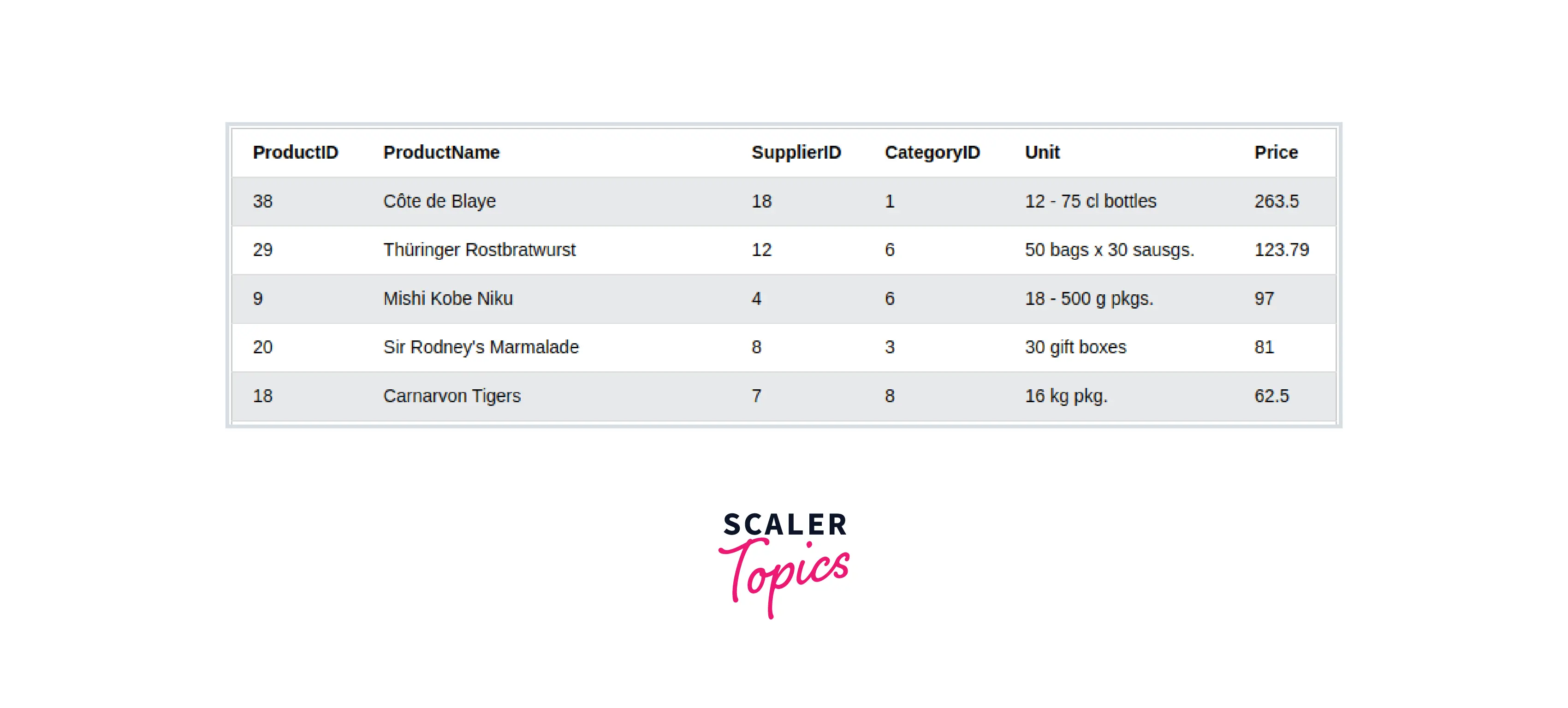
- Sort Data with Respect to a Column Data can be sorted according to a column or a list of columns in a dataframe using the .sort_values method. We can pass (list of) columns as arguments and specify the order as bool(s) to the ascending parameter. This can also be done in-place (modifying the dataframe) with inplace=True.
- Display the Mean of Each Column The .mean method displays the means of each column in a pandas dataframe, skipping the Null values by default.
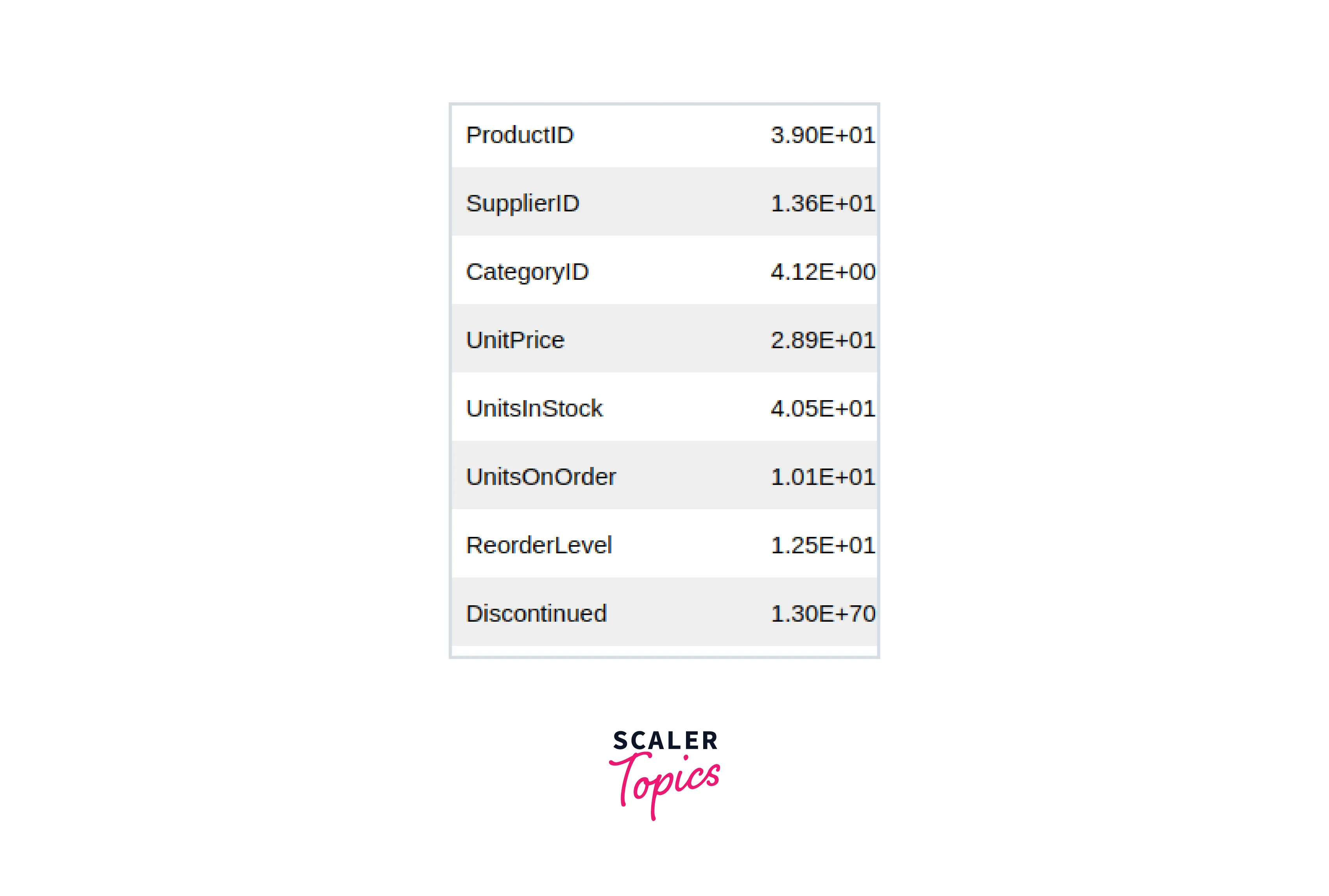
- Rename the Dataframe Columns using rename() We can modify column names that are loaded into the pandas dataframe from the database table using the .rename method and provide a dict object to map existing column names to desired ones.
Use read_sql_query() Method to Execute SQL Query
Pandas provide a clean interface to directly store the result of an SQL query into a pandas Dataframe utilizing its read_sql_query() method. It takes the SQL query and database connection as its arguments and returns a dataframe populated with the query results.
Use to_sql() Method Write into SQL Table
Once we load data in a dataframe, we can perform various operations on it and manipulate data as required. Conversely, this data can also be stored/saved into a database table using the to_sql method to write the data into a database table from the dataframe. We provide the name of the table and a connection object to the method to write the dataframe to the database.
Note that, with some databases, writing a large DataFrame may result in errors due to limitations on packet size, for this use the chunksize argument to specify the number of rows written in each chunk_
Use read_sql() Method
The read_sql method of Pandas dataframe is a wrapper around the read_sql_table and read_sql_query methods which are delegated based on the kind of argument given, SQL queries call the read_sql_query method, and table names are redirected to read_sql_table.
Using an SQLite database only allows SQL queries; providing only the Database table name will result in an error.
Conclusion
- In this article, we covered how databases work with pandas' dataframes and techniques we may use to read, modify and write data to and from database tables utilizing dataframes and pandas methods.
- Pandas allows us to conveniently read data from databases using queries and table names, which can be accessed and operated on using dataframes.
- Pandas dataframes can be utilized to perform operations on and analyze the Database tables read in as data frames because they provide a simplified interface than raw SQL queries to manipulate data to generate insights.
- Finally, we also take a look at how to write the modified data to the database using the to_sql() method.