Read CSV File in Python Pandas
Learn via video courses
Overview
Every deep learning model demands data, and CSV is one of the most widely used data transmission formats. CSV files (Comma Separated Values files) are a type of basic text document that uses a specialized structure to arrange tabular data. A comma delimits each item of data. As you can expect, data sizes are often immense for any deep learning model, and CSV files aid in the organizing of massive amounts of data. When managing big volumes of data or doing quantitative analysis, the pandas library outperforms all other Pandas modules in terms of CSV parsing.
Scope of the Article
In this article,
- We will look at the intricacies of CSV and its significance in Pandas.
- We will also look at its syntax and parameters.
- We'll also look at other ways to read CSV files in python pandas into a DataFrame, including an example.
- In addition, we'll look into how to display huge tables in Pandas.
- Finally, we'll consider converting our CSV file to string format, followed by an example.
Introduction
Every machine learning model craves data. We must get data to/from our programs. Text file exchange is a typical method for sharing information between applications. The CSV format is among the most widely used data exchange formats. How do we employ it, though?
What is a CSV File? Why is It Used in Pandas?
So, what exactly is a CSV file? CSV files, which stands for Comma Separated Values files, are a simple text document that employs a specialized structure to organize tabular information. Because it is a simple text file, it could only include textual information; that is, readable ASCII or Unicode characters.
The full title of a CSV file reveals the underlying format. CSV files typically employ a comma to separate every data value. This is how the structure appears:
Sample CSV File
Observe that each data item is delimited by a comma. In most cases, the first line specifies each data item—the column header's title. Every succeeding line contains actual information and is restricted by file capacity limits.
The separating symbol is known as a delimiter; the comma isn't the only one employed in practice. Other often used delimiters encompass the tab (t), colon (:), and semicolon (;) symbols. Now that we've defined what we meant by a CSV file let's look at why they're the first choice for storing data in Pandas.
Why is It Used in Pandas?
Among the most prevalent reasons that CSV is the primary choice for storing data are:
- Because CSV files are simple text files, they are easier for website developers to construct.
- They're easy to import into a tabular format (Like Excel) or another storage database (Like SQL) since they're simple text, independent of the program we're employing.
- To improve the organization of enormous volumes of data.
CSV Module Functions
We do not need to create our custom CSV parser from scratch. We can use several suitable libraries. For the most part, the Python CSV module should do. The CSV module is specially designed to handle this operation, making it much simpler to work with CSV files. This is especially useful when working with data generated to text files from databases (Like SQL) and Excel spreadsheets. This data might be difficult to comprehend on its own.
If your project involves a huge amount of data or quantitative analysis, the pandas library offers CSV parsing capabilities that should take care of the rest. This post will explore how to parse and modify data using the Pandas Library.
Understanding the read_csv() Function
To access data from a CSV file, use the read_csv() method. The read_csv() function has the following syntax:
Syntax
pandas.read_csv(filepath_or_buffer, sep=NoDefault.no_default, delimiter=None, header='infer', names=NoDefault.no_default, index_col=None, usecols=None, squeeze=None, prefix=NoDefault.no_default, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, skipfooter=0, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=None, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, cache_dates=True, iterator=False, chunksize=None, compression='infer', thousands=None, decimal='.', lineterminator=None, quotechar='"', quoting=0, doublequote=True, escapechar=None, comment=None, encoding=None, encoding_errors='strict', dialect=None, error_bad_lines=None, warn_bad_lines=None, on_bad_lines=None, delim_whitespace=False, low_memory=True, memory_map=False, float_precision=None, storage_options=None)
The following is a list of parameters, along with their default settings. Although not all of them are particularly critical, memorizing them might save you time when conducting some tasks on your own. To examine the arguments of the read_csv() method, use shift + tab in jupyter notebook, or check the Pandas official documentation. The following are useful ones, along with their applications:
Parameter List
| Sr. NO. | Parameter Name | Parameter description |
|---|---|---|
| 1 | filepath_or_buffer | This method returns the file path to be fetched. It takes any file location or URL string. |
| 2 | sep | It is an abbreviation for separator; the default is ',' as in csv file. |
| 3 | header | It receives an integer, a list of integers, row values to use as column names, and the beginning of the data. If no names are given, i.e the header is set as None, the very first column will be shown as 0, the following as 1, and so on. |
| 4 | usecols | This command obtains only specific columns from a csv file. |
| 5 | nrows | This is the number of rows from the dataset that will be presented. |
| 6 | index_col | If set as None, no index numerals are shown with the data. |
| 7 | squeeze | If it is set as true and only a single column is given, pandas series is returned. |
| 8 | skiprows | Skips previously passed rows in the new DataFrame. |
| 9 | names | It enables the retrieval of columns using different names. |
How to Load the CSV into a DataFrame?
Now that we've gone through the syntax of the read_csv() method, let's look at some practical applications. Pandas's read_csv() method converts a CSV file to Pandas DataFrame format. As previously stated, based on the functionality we desire, we may provide a variety of parameters to our read_csv() method. Let's start by just supplying the filepath_or_buffer and seeing what happens.
Code:
Output:

It read CSV files in python pandas from the path we supplied. What if we want greater control over how our CSV file is loaded? For example, imagine we want to explicitly choose which row will be employed as column labels for your DataFrame. We will employ the header parameter for this functionality. The default value for header is 0, which implies that the very first row of the CSV file will serve as column labels. If your file lacks a header, just assign the header to None.
Code:
Output:
We may also use another delimiter than a comma to parse our csv file. However, the delimiter in our case is a comma, which is the default value of the sep argument.
We may use the index_col argument to specify which columns would be employed as the DataFrame's index.
Code:
Output:
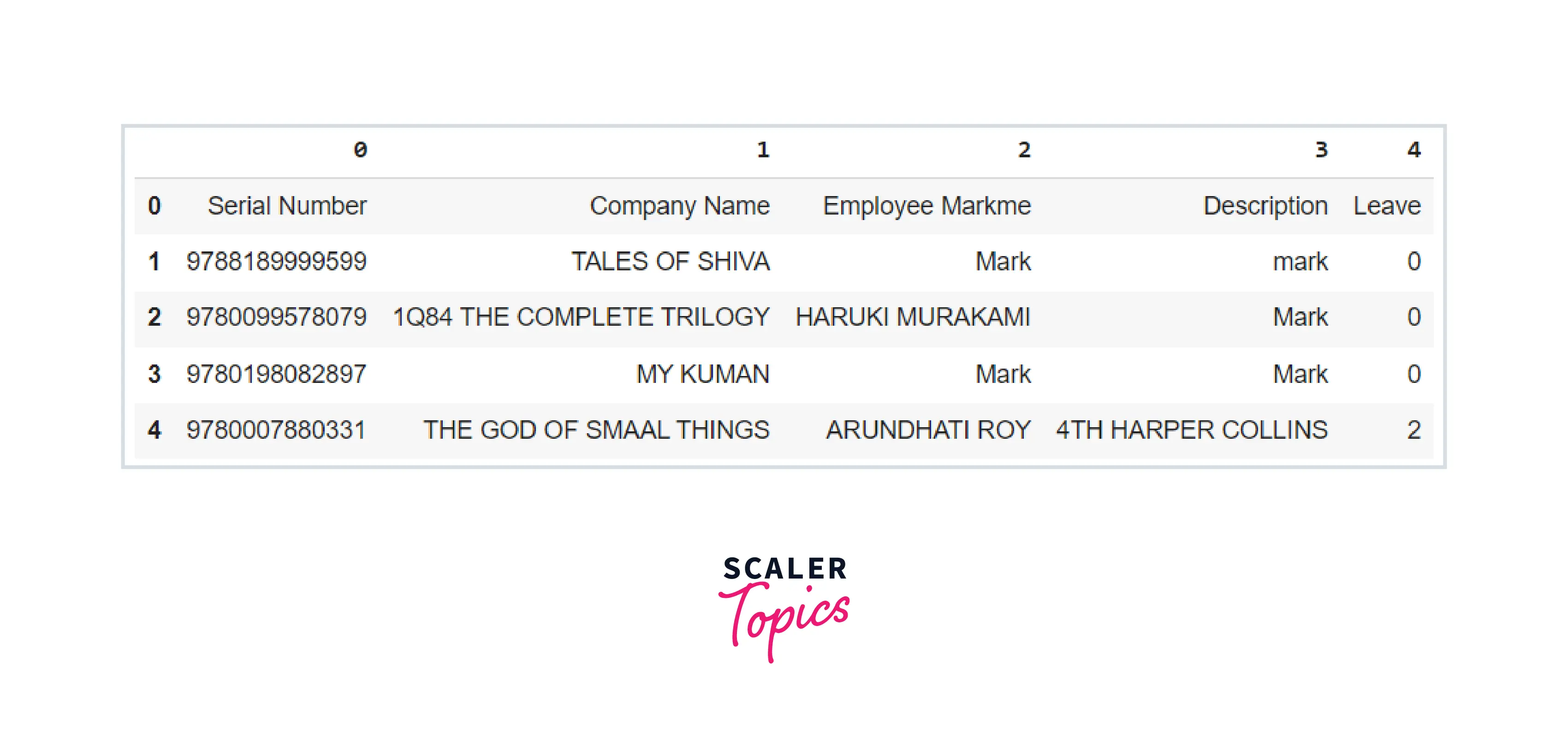
Assume we simply need to read the first given number of rows from the file or load a CSV file with a defined list of columns to load into the DataFrame. We can leverage the nrows and usecols arguments to our advantage, respectively.
Code:
Output:

Now that we've seen how to load a CSV file into a DataFrame, let's look at how to load a CSV file into a Python dictionary.
How to Read a CSV File in Python Dictionary?
Once we understand how to load a CSV file in Pandas DataFrame, reading a CSV file in Python Dictionary becomes pretty simple. To read CSV file in Python Pandas dictionary, first read our file in a DataFrame using the read_csv() method, then transform the output to a dictionary employing the inbuilt Pandas DataFrame method to_dict().
Code:
Output:
What is the to_string Method in Pandas?
So far, we've seen how to load a CSV file in either DataFrame or Python dictionary format. However, we discovered that we could only print a small portion of our dataset. What if we want to print our complete dataset, which isn't massive; it's in the millions or billions. The to_string() function is the simplest; it turns the whole Pandas DataFrame into a string object and works effectively for DataFrames with thousands of rows.
Code:
Output:
How to Print a DataFrame Without Using the to_string() method
To print the complete CSV file, we may use the following method instead of the to_string() method:
- Using pd.option_context() Method
- Using pd.set_options() Method
- Using pd.to_markdown() Method
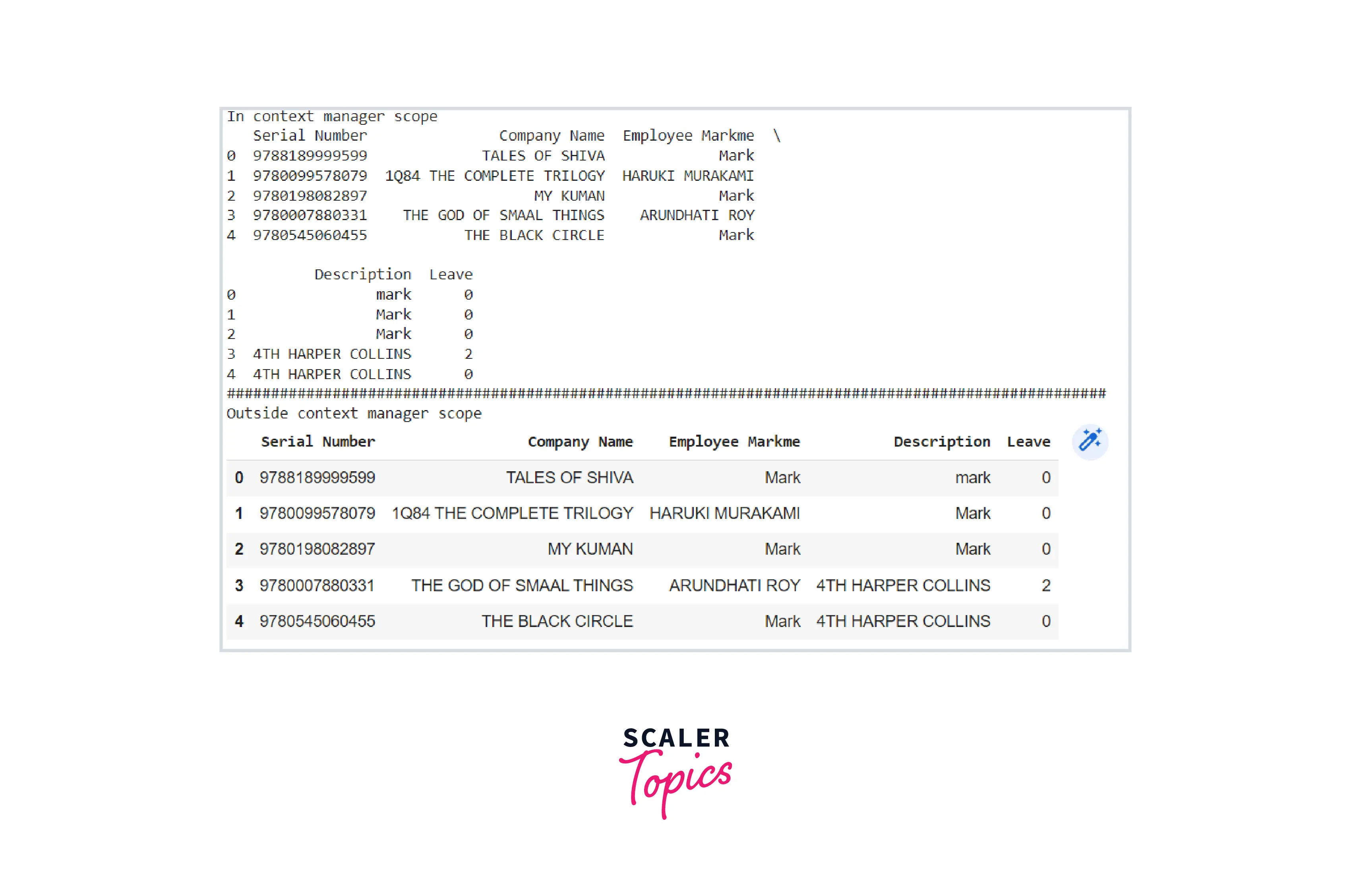
Pandas' option_context() and set_option() functions allow us to modify settings. Both techniques are identical, except that the latter modifies the settings forever, and the former does so only inside the context manager scope. To further comprehend it, consider the following code example.
Code:
Output:
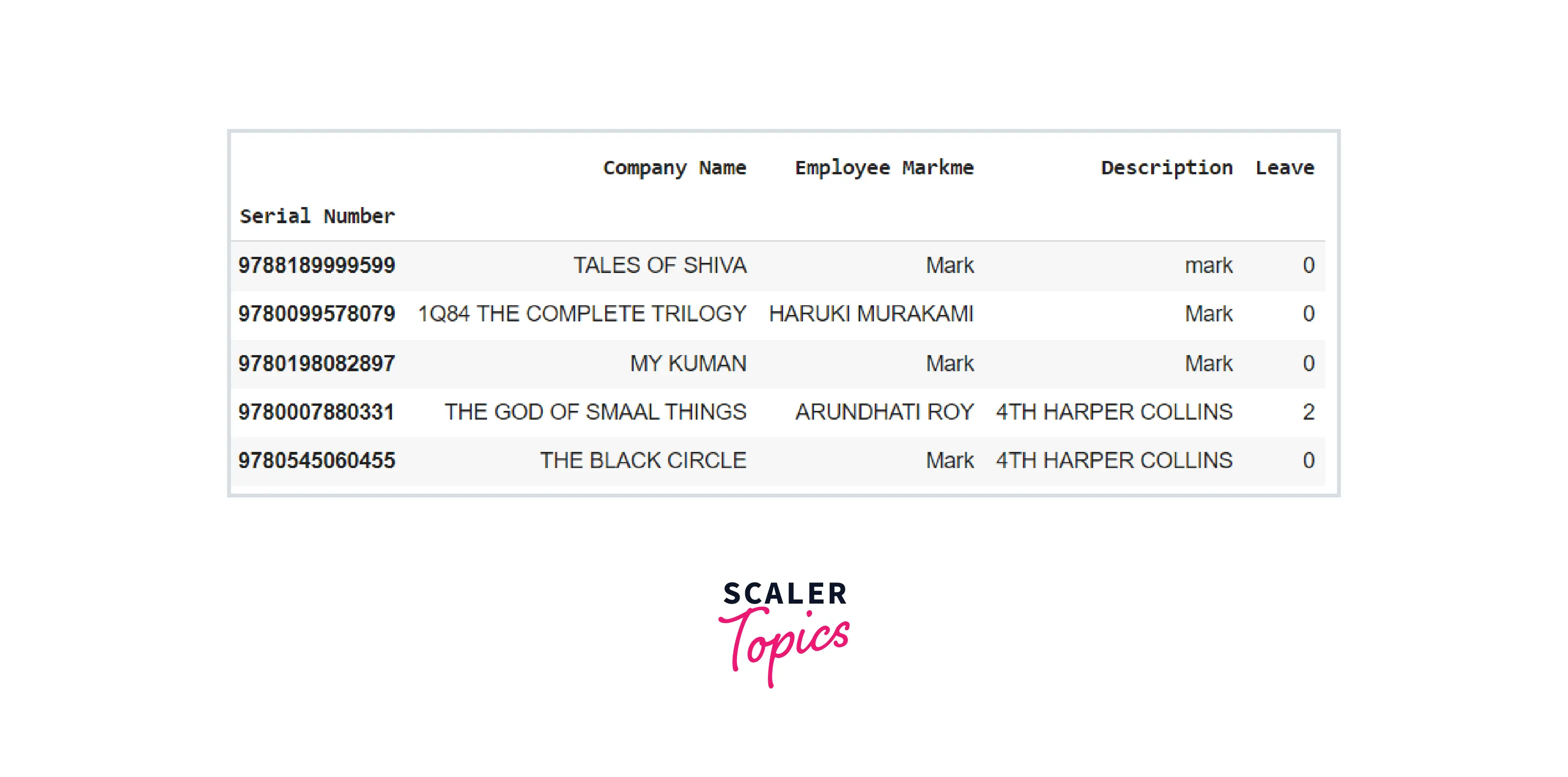
Code:
Output:
Pandas's to_markdown() function is similar to the to_string() function in that it transforms the DataFrame to a string object and adds styling and formatting. Consider the following example:
Code:
Output:
| Serial Number | Company Name | Employee Markme | Description | Leave | |
|---|---|---|---|---|---|
| 0 | 9788189999599 | TALES OF SHIVA | Mark | mark | 0 |
| 1 | 9780099578079 | 1Q84 THE COMPLETE TRILOGY | HARUKI MURAKAMI | Mark | 0 |
| 2 | 9780198082897 | MY KUMAN | Mark | Mark | 0 |
| 3 | 9780007880331 | THE GOD OF SMAAL THINGS | ARUNDHATI ROY | 4TH HARPER COLLINS | 2 |
| 4 | 9780545060455 | THE BLACK CIRCLE | Mark | 4TH HARPER COLLINS | 0 |
| 5 | 9788126525072 | THE THREE LAWS OF PERFORMANCE | Mark | 4TH HARPER COLLINS | 0 |
| 6 | 9789381626610 | CHAMarkKYA MANTRA | Mark | 4TH HARPER COLLINS | 0 |
| 7 | 9788184513523 | 59.FLAGS | Mark | 4TH HARPER COLLINS | 0 |
| 8 | 9780743234801 | THE POWER OF POSITIVE THINKING FROM | Mark | A & A PUBLISHER | 0 |
| 9 | 9789381529621 | YOU CAN IF YO THINK YO CAN | PEALE | A & A PUBLISHER | 0 |
| 10 | 9788183223966 | DONGRI SE DUBAI TAK (MPH) | Mark | A & A PUBLISHER | 0 |
| 11 | 9788187776005 | MarkLANDA ADYTAN KOSH | Mark | AADISH BOOK DEPOT | 0 |
| 12 | 9788187776013 | MarkLANDA VISHAL SHABD SAGAR | - | AADISH BOOK DEPOT | 1 |
| 13 | 8187776021 | MarkLANDA CONCISE DICT(ENG TO HINDI) | Mark | AADISH BOOK DEPOT | 0 |
| 14 | 9789384716165 | LIEUTEMarkMarkT GENERAL BHAGAT: A SAGA OF BRAVERY AND LEADERSHIP | Mark | AAM COMICS | 2 |
| 15 | 9789384716233 | LN. MarkIK SUNDER SINGH | N.A | AAN COMICS | 0 |
| 16 | 9789384850319 | I AM KRISHMark | DEEP TRIVEDI | AATMAN INNOVATIONS PVT LTD | 1 |
| 17 | 9789384850357 | DON'T TEACH ME TOLERANCE INDIA | DEEP TRIVEDI | AATMAN INNOVATIONS PVT LTD | 0 |
| 18 | 9789384850364 | MUJHE SAHISHNUTA MAT SIKHAO BHARAT | DEEP TRIVEDI | AATMAN INNOVATIONS PVT LTD | 0 |
| 19 | 9789384850746 | SECRETS OF DESTINY | DEEP TRIVEDI | AATMAN INNOVATIONS PVT LTD | 1 |
| 20 | 9789384850753 | BHAGYA KE RAHASYA (HINDI) SECRET OF DESTINY | DEEP TRIVEDI | AATMAN INNOVATIONS PVT LTD | 1 |
| 21 | 9788192669038 | MEIN MANN HOON | DEEP TRIVEDI | AATMAN INNOVATIONS PVT LTD | 0 |
| 22 | 9789384850098 | I AM THE MIND | DEEP TRIVEDI | AATMARAM & SONS | 0 |
| 23 | 9780349121420 | THE ART OF CHOOSING | SHEEMark IYENGAR | ABACUS | 0 |
| 24 | 9780349123462 | IN SPITE OF THE GODS | EDWARD LUCE | ABACUS | 1 |
| 25 | 9788188440061 | QUESTIONS & ANWERS ABOUT THE GREAT BIBLE | Mark | ABC PUBLISHERS DISTRIBUTORS | 4 |
| 26 | 9789382088189 | NIBANDH EVAM KAHANI LEKHAN { HINDI } | Mark | ABHI BOOKS | 1 |
| 27 | 9789332703759 | INDIAN ECONOMY SINCE INDEPENDENCE 27TH /E | UMA KAPILA | ACADEMIC FOUNDATION | 1 |
| 28 | 9788171888016 | ECONOMIC DEVELOPMENT AND POLICY IN INDIA | UMA KAPILA | ACADEMIC FOUNDATION | 1 |
| 29 | 9789332704343 | INDIAN ECONOMY PERFORMANCE 18TH/E 2017-2018 | UMA KAPILA | ACADEMIC FOUNDATION | 2 |
| 30 | 9789332703735 | INDIAN ECONOMIC DEVELOPMENTSINCE 1947 (NO RETURMarkBLE) | UMA KAPILA | ACADEMIC FOUNDATION | 1 |
| 31 | 9789383454143 | PRELIMS SPECIAL READING COMPREHENSION PAPER II CSAT | MarkGENDRA PRATAP | ACCESS PUBLISHING INDIA PVT.LTD | 0 |
| 32 | 9789383454204 | THE CONSTITUTION OF INDIA 2ND / E | AR KHAN | ACCESS PUBLISHING INDIA PVT.LTD | 10 |
| 33 | 9789386361011 | INDIAN HERITAGE ,ART & CULTURE | MADHUKAR | ACCESS PUBLISHING INDIA PVT.LTD | 10 |
| 34 | 9789383454303 | BHARAT KA SAMVIDHAN | AR KHAN | ACCESS PUBLISHING INDIA PVT.LTD | 4 |
| 35 | 9789383454471 | ETHICS, INTEGRITY & APTITUDE ( 3RD/E) | P N ROY ,G SUBBA RAO | ACCESS PUBLISHING INDIA PVT.LTD | 10 |
| 36 | 9789383454563 | GENERAL STUDIES PAPER -- I (2016) | Mark | ACCESS PUBLISHING INDIA PVT.LTD | 0 |
| 37 | 9789383454570 | GENERAL STUDIES PAPER - II (2016) | Mark | ACCESS PUBLISHING INDIA PVT.LTD | 0 |
| 38 | 9789383454693 | INDIAN AND WORLD GEOGRAPHY 2E | D R KHULLAR | ACCESS PUBLISHING INDIA PVT.LTD | 10 |
| 39 | 9789383454709 | VASTUNISTHA PRASHN SANGRAHA: BHARAT KA ITIHAS | MEEMarkKSHI KANT | ACCESS PUBLISHING INDIA PVT.LTD | 0 |
| 40 | 9789383454723 | PHYSICAL, HUMAN AND ECONOMIC GEOGRAPHY | D R KHULLAR | ACCESS PUBLISHING INDIA PVT.LTD | 4 |
| 41 | 9789383454730 | WORLD GEOGRAPHY | DR KHULLAR | ACCESS PUBLISHING INDIA PVT.LTD | 5 |
| 42 | 9789383454822 | INDIA: MAP ENTRIES IN GEOGRAPHY | MAJID HUSAIN | ACCESS PUBLISHING INDIA PVT.LTD | 5 |
| 43 | 9789383454853 | GOOD GOVERMarkNCE IN INDIA 2/ED. | G SUBBA RAO | ACCESS PUBLISHING INDIA PVT.LTD | 1 |
| 44 | 9789383454884 | KAMYABI KE SUTRA-CIVIL SEWA PARIKSHA AAP KI MUTTHI MEIN | ASHOK KUMAR | ACCESS PUBLISHING INDIA PVT.LTD | 0 |
| 45 | 9789383454891 | GENERAL SCIENCE PRELIRY EXAM | Mark | ACCESS PUBLISHING INDIA PVT.LTD | 0 |
| 46 | 9781742860190 | SUCCESS AND DYSLEXIA | SUCCESS AND DYSLEXIA | ACER PRESS | 0 |
| 47 | 9781742860114 | AN EXTRAORDIMarkRY SCHOOL | SARA JAMES | ACER PRESS | 0 |
| 48 | 9781742861463 | POWERFUL PRACTICES FOR READING IMPROVEMENT | GLASSWELL | ACER PRESS | 0 |
| 49 | 9781742862859 | EARLY CHILDHOOD PLAY MATTERS | SHOMark BASS | ACER PRESS | 0 |
| 50 | 9781742863641 | LEADING LEARNING AND TEACHING | STEPHEN DINHAM | ACER PRESS | 0 |
| 51 | 9781742863658 | READING AND LEARNING DIFFICULTIES | PETER WESTWOOD | ACER PRESS | 0 |
| 52 | 9781742863665 | NUMERACY AND LEARNING DIFFICULTIES | PETER WOODLAND] | ACER PRESS | 0 |
| 53 | 9781742863771 | TEACHING AND LEARNING DIFFICULTIES | PETER WOODLAND | ACER PRESS | 0 |
| 54 | 9781742861678 | USING DATA TO IMPROVE LEARNING | ANTHONY SHADDOCK | ACER PRESS | 0 |
| 55 | 9781742862484 | PATHWAYS TO SCHOOL SYSTEM IMPROVEMENT | MICHAEL GAFFNEY | ACER PRESS | 0 |
| 56 | 9781742860176 | FOR THOSE WHO TEACH | PHIL RIDDEN | ACER PRESS | 0 |
| 57 | 9781742860213 | KEYS TO SCHOOL LEADERSHIP | PHIL RIDDEN & JOHN DE NOBILE | ACER PRESS | 0 |
| 58 | 9781742860220 | DIVERSE LITERACIES IN EARLY CHILDHOOD | LEONIE ARTHUR | ACER PRESS | 0 |
| 59 | 9781742860237 | CREATIVE ARTS IN THE LIVESOF YOUNG CHILDREN | ROBYN EWING | ACER PRESS | 0 |
| 60 | 9781742860336 | SOCIAL AND EMOTIOMarkL DEVELOPMENT | ROS LEYDEN AND ERIN SHALE | ACER PRESS | 0 |
| 61 | 9781742860343 | DISCUSSIONS IN SCIENCE | TIM SPROD | ACER PRESS | 0 |
| 62 | 9781742860404 | YOUNG CHILDREN LEARNING MATHEMATICS | ROBERT HUNTING | ACER PRESS | 0 |
| 63 | 9781742860626 | COACHING CHILDREN | KELLY SUMICH | ACER PRESS | 1 |
| 64 | 9781742860923 | TEACHING PHYSICAL EDUCATIOMarkL IN PRIMARY SCHOOL | JANET L CURRIE | ACER PRESS | 0 |
| 65 | 9781742861111 | ASSESSMENT AND REPORTING | PHIL RIDDEN AND SANDY | ACER PRESS | 0 |
| 66 | 9781742861302 | COLLABORATION IN LEARNING | MAL LEE AND LORRAE WARD | ACER PRESS | 0 |
| 67 | 9780864315250 | RE-IMAGINING EDUCATIMarkL LEADERSHIP | BRIAN J.CALDWELL | ACER PRESS | 0 |
| 68 | 9780864317025 | TOWARDS A MOVING SCHOOL | FLEMING & KLEINHENZ | ACER PRESS | 0 |
| 69 | 9780864317230 | DESINGNING A THINKING A CURRICULAM | SUSAN WILKS | ACER PRESS | 0 |
| 70 | 9780864318961 | LEADING A DIGITAL SCHOOL | MAL LEE AND MICHEAL GAFFNEY | ACER PRESS | 0 |
| 71 | 9780864319043 | NUMERACY | WESTWOOD | ACER PRESS | 0 |
| 72 | 9780864319203 | TEACHING ORAL LANGUAGE | JOHN MUNRO | ACER PRESS | 0 |
| 73 | 9780864319449 | SPELLING | WESTWOOD | ACER PRESS | 0 |
| 74 | 9788189999803 | STORIES OF SHIVA | Mark | ACK | 0 |
| 75 | 9788189999988 | JAMSET JI TATA: THE MAN WHO SAW TOMORROW | nan | ACK | 0 |
| 76 | 9788184820355 | HEROES FROM THE MAHABHARTA { 5-IN-1 } | Mark | ACK | 0 |
| 77 | 9788184820553 | SURYA | nan | ACK | 0 |
| 78 | 9788184820645 | TALES OF THE MOTHER GODDESS | - | ACK | 0 |
| 79 | 9788184820652 | ADVENTURES OF KRISHMark | Mark | ACK | 0 |
| 80 | 9788184822113 | MAHATMA GANDHI | Mark | ACK | 1 |
| 81 | 9788184822120 | TALES FROM THE PANCHATANTRA 3-IN-1 | - | ACK | 0 |
| 82 | 9788184821482 | YET MORE TALES FROM THE JATAKAS { 3-IN-1 } | AMarkNT PAI | ACK | 0 |
| 83 | 9788184825763 | LEGENDARY RULERS OF INDIA | - | ACK | 0 |
| 84 | 9788184825862 | GREAT INDIAN CLASSIC | Mark | ACK | 0 |
| 85 | 9788184823219 | TULSIDAS ' RAMAYAMark | Mark | ACK | 0 |
| 86 | 9788184820782 | TALES OF HANUMAN | - | ACK | 0 |
| 87 | 9788184820089 | VALMIKI'S RAMAYAMark | A C K | ACK | 1 |
| 88 | 9788184825213 | THE BEST OF INIDAN WIT AND WISDOM | Mark | ACK | 0 |
| 89 | 9788184820997 | MORE TALES FROM THE PANCHTANTRA | AMarkNT PAL | ACK | 0 |
| 90 | 9788184824018 | THE GREAT MUGHALS {5-IN-1} | AMarkNT. | ACK | 0 |
| 91 | 9788184824049 | FAMOUS SCIENTISTS | Mark | ACK | 0 |
| 92 | 9788184825978 | KOMarkRK | Mark | ACK | 0 |
| 93 | 9788184826098 | THE MUGHAL COURT | REEMark | ACK | 0 |
| 94 | 9788184821536 | MORE STORIES FROM THE JATAKAS | Mark | ACK | 0 |
| 95 | 9788184821543 | MORE TALES OF BIRBAL | - | ACK | 0 |
| 96 | 9788184821550 | TALES FROM THE JATAKAS | - | ACK | 0 |
| 97 | 9788184821567 | RAMarkS OF MEWAR | - | ACK | 0 |
| 98 | 9788184821574 | THE SONS OF THE PANDAVAS | - | ACK | 0 |
How to Check the Number of Maximum Returned Rows?
Now that we've looked at how to load a CSV file let's look at different methods for calculating the total number of rows in our data.
We may use any of the methods listed below to count the number of rows in our data:
- Using len() function
The len() built-in function is the simplest and clearest way to determine the row count of a DataFrame. Consider the following code example to better understand it.
Code:
Output:
- Using shape attribute
Similarly, pandas. DataFrame.shape can produce a tuple describing the DataFrame's dimensionality. The first tuple member reflects the number of rows, while the second member denotes the number of columns. To further understand it, consider the following code sample.
Code:
Output:
- Using count function
The third and final option for determining row counts in Pandas is the DataFrame.count() method, which provides the total count for non-NAN values. Consider the following example.
Code:
Output:
This leads us to the end of our article. Kudos! You now have a firm grasp on importing and altering data from a CSV file.
Conclusion
This article taught us:
- CSV files, stands for Comma Separated Values files.
- In a CSV file, each data item is delimited by a comma.
- CSV files are simple text files. They are easier to import into a tabular format (Like Excel) or other storage database (Like SQL). It also helps to improve the organization of enormous volumes of data.
- When handling large amounts of data or doing quantitative analysis, the pandas library has greater CSV parsing capabilities than any other module in Pandas.
- To read a CSV file in python pandas into a DataFrame, Pandas library offers a simple function; read_csv() that loads data from a CSV file to a DataFrame. read_csv() functions provide a wide range of arguments we can alter according to the functionality we desire.
- To get the total number of records in our data, we can use the len() function, the count function, or the shape attribute.